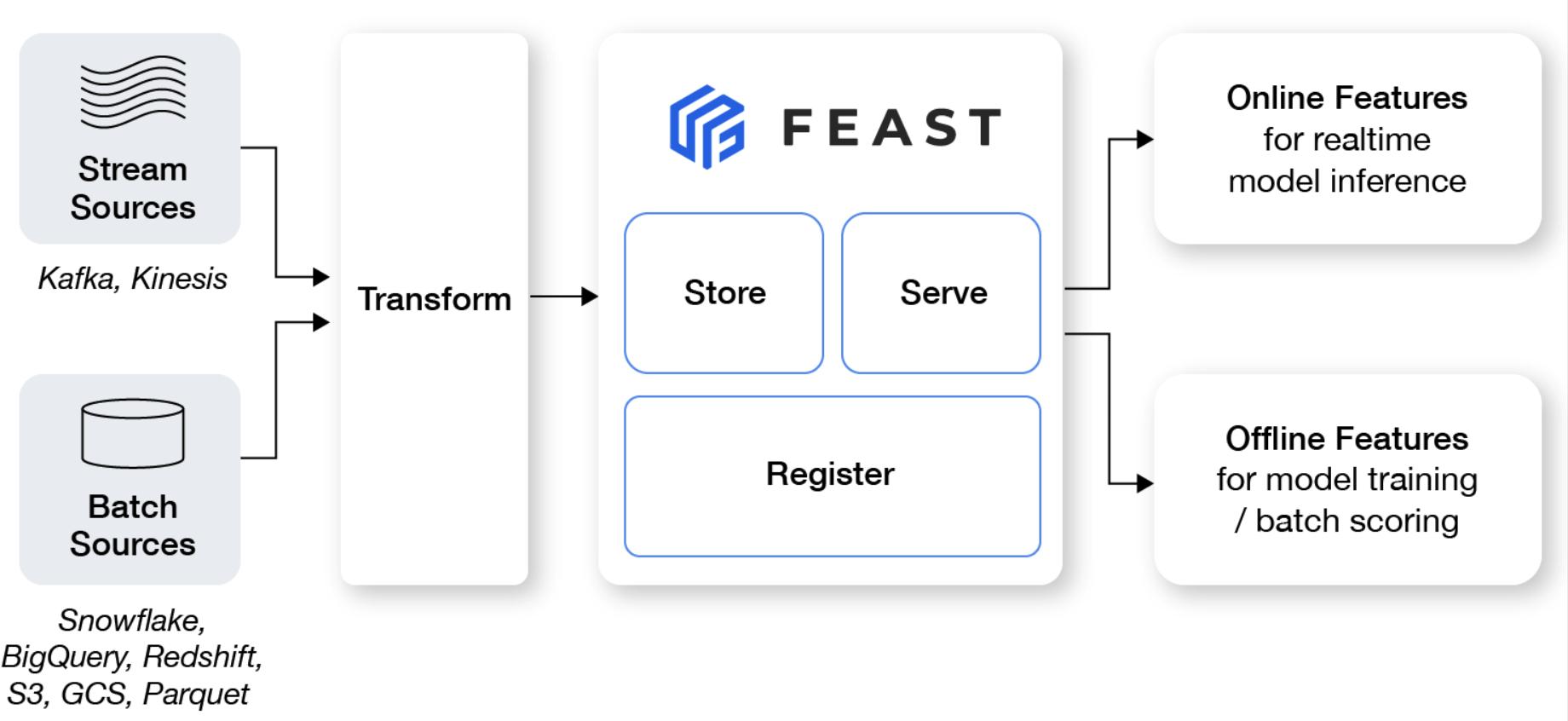
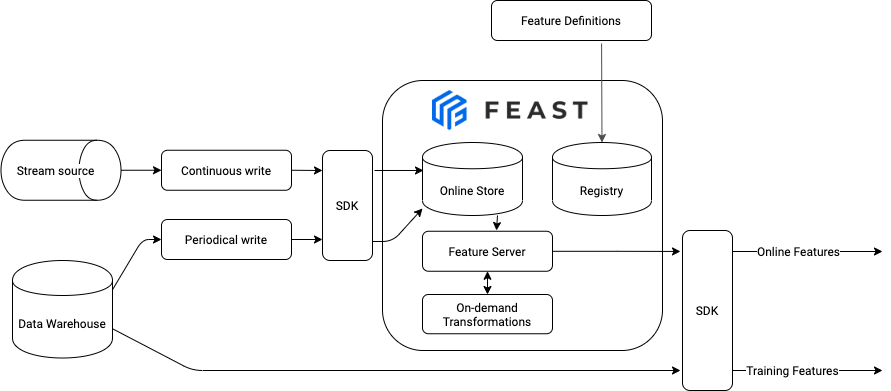
One can use existing plugins (offline store, online store, batch materialization engine, providers) and configure those using the built in options. See reference documentation for details.
The other way to customize Feast is to build your own custom components, and then point Feast to delegate to them.
Below are some guides on how to add new custom components:
Feast supports registering streaming feature views and Kafka and Kinesis streaming sources. It also provides an interface for stream processing called the Stream Processor. An example Kafka/Spark StreamProcessor is implemented in the contrib folder. For more details, please see the RFC for more details.
Please see here for a tutorial on how to build a versioned streaming pipeline that registers your transformations, features, and data sources in Feast.
Batch Materialization Engine
A batch materialization engine is a component of Feast that's responsible for moving data from the offline store into the online store.
A materialization engine abstracts over specific technologies or frameworks that are used to materialize data. It allows users to use a pure local serialized approach (which is the default LocalMaterializationEngine), or delegates the materialization to seperate components (e.g. AWS Lambda, as implemented by the the LambdaMaterializaionEngine).
If the built-in engines are not sufficient, you can create your own custom materialization engine. Please see this guide for more details.
Community Governance Doc: See the governance model of Feast, including who the maintainers are and how decisions are made.
: This folder is used as a central repository for all Feast resources. For example:
Design proposals in the form of Request for Comments (RFC).
User surveys and meeting minutes.
Slide decks of conferences our contributors have spoken at.
: Our LFAI wiki page contains links to resources for contributors and maintainers.
GitHub Issues: Found a bug or need a feature? .
Third party integrations
We integrate with a wide set of tools and technologies so you can make Feast work in your existing stack. Many of these integrations are maintained as plugins to the main Feast repo.
See
In order for a plugin integration to be highlighted, it must meet the following requirements:
The plugin must have tests. Ideally it would use the Feast universal tests (see this for an example), but custom tests are fine.
Deploy a feature store
The Feast CLI can be used to deploy a feature store to your infrastructure, spinning up any necessary persistent resources like buckets or tables in data stores. The deployment target and effects depend on the provider that has been configured in your file, as well as the feature definitions found in your feature repository.
To have Feast deploy your infrastructure, run feast apply from your command line while inside a feature repository:
Depending on whether the feature repository is configured to use a local provider or one of the cloud providers like GCP or AWS, it may take from a couple of seconds to a minute to run to completion.
Real-time credit scoring on AWS
Credit scoring models are used to approve or reject loan applications. In this tutorial we will build a real-time credit scoring system on AWS.
When individuals apply for loans from banks and other credit providers, the decision to approve a loan application is often made through a statistical model. This model uses information about a customer to determine the likelihood that they will repay or default on a loan, in a process called credit scoring.
In this example, we will demonstrate how a real-time credit scoring system can be built using Feast and Scikit-Learn on AWS, using feature data from S3.
This real-time system accepts a loan request from a customer and responds within 100ms with a decision on whether their loan has been approved or rejected.
This end-to-end tutorial will take you through the following steps:
Scaling Feast
Feast is designed to be easy to use and understand out of the box, with as few infrastructure dependencies as possible. However, there are components used by default that may not scale well. Since Feast is designed to be modular, it's possible to swap such components with more performant components, at the cost of Feast depending on additional infrastructure.
The default Feast is a file-based registry. Any changes to the feature repo, or materializing data into the online store, results in a mutation to the registry.
However, there are inherent limitations with a file-based registry, since changing a single field in the registry requires re-writing the whole registry file. With multiple concurrent writers, this presents a risk of data loss, or bottlenecks writes to the registry since all changes have to be serialized (e.g. when running materialization for multiple feature views or time ranges concurrently).
The recommended solution in this case is to use the , which allows concurrent, transactional, and fine-grained updates to the registry. This registry implementation requires access to an existing database (such as MySQL, Postgres, etc).
Load data into the online store
Feast allows users to load their feature data into an online store in order to serve the latest features to models for online prediction.
Before proceeding, please ensure that you have applied (registered) the feature views that should be materialized.
The materialize command allows users to materialize features over a specific historical time range into the online store.
The above command will query the batch sources for all feature views over the provided time range, and load the latest feature values into the configured online store.
It is also possible to materialize for specific feature views by using the -v / --views argument.
The materialize command is completely stateless. It requires the user to provide the time ranges that will be loaded into the online store. This command is best used from a scheduler that tracks state, like Airflow.
Fraud detection on GCP
A common use case in machine learning, this tutorial is an end-to-end, production-ready fraud prediction system. It predicts in real-time whether a transaction made by a user is fraudulent.
Throughout this tutorial, we’ll walk through the creation of a production-ready fraud prediction system. A prediction is made in real-time as the user makes the transaction, so we need to be able to generate a prediction at low latency.
Our end-to-end example will perform the following workflows:
Computing and backfilling feature data from raw data
Offline store
An offline store is an interface for working with historical time-series feature values that are stored in . The OfflineStore interface has several different implementations, such as the BigQueryOfflineStore, each of which is backed by a different storage and compute engine. For more details on which offline stores are supported, please see .
Offline stores are primarily used for two reasons:
Building training datasets from time-series features.
File
File data sources are files on disk or on S3. Currently only Parquet files are supported.
The full set of configuration options is available .
File data sources support all eight primitive types and their corresponding array types. For a comparison against other batch data sources, please see .
Snowflake
Snowflake data sources are Snowflake tables or views. These can be specified either by a table reference or a SQL query.
Using a table reference:
Using a query:
The full set of configuration options is available .
Snowflake data sources support all eight primitive types, but currently do not support array types. For a comparison against other batch data sources, please see .
BigQuery
BigQuery data sources are BigQuery tables or views. These can be specified either by a table reference or a SQL query. However, no performance guarantees can be provided for SQL query-based sources, so table references are recommended.
Using a table reference:
Using a query:
The full set of configuration options is available .
BigQuery data sources support all eight primitive types and their corresponding array types. For a comparison against other batch data sources, please see .
Redshift
Redshift data sources are Redshift tables or views. These can be specified either by a table reference or a SQL query. However, no performance guarantees can be provided for SQL query-based sources, so table references are recommended.
Using a table name:
Using a query:
The full set of configuration options is available .
Redshift data sources support all eight primitive types, but currently do not support array types. For a comparison against other batch data sources, please see .
PostgreSQL (contrib)
PostgreSQL data sources are PostgreSQL tables or views. These can be specified either by a table reference or a SQL query.
The PostgreSQL data source does not achieve full test coverage. Please do not assume complete stability.
Defining a Postgres source:
The full set of configuration options is available .
PostgreSQL data sources support all eight primitive types and their corresponding array types. For a comparison against other batch data sources, please see .
Trino (contrib)
Trino data sources are Trino tables or views. These can be specified either by a table reference or a SQL query.
The Trino data source does not achieve full test coverage. Please do not assume complete stability.
Defining a Trino source:
The full set of configuration options is available .
Trino data sources support all eight primitive types, but currently do not support array types. For a comparison against other batch data sources, please see .
Online store
Feast uses online stores to serve features at low latency. Feature values are loaded from data sources into the online store through materialization, which can be triggered through the materialize command.
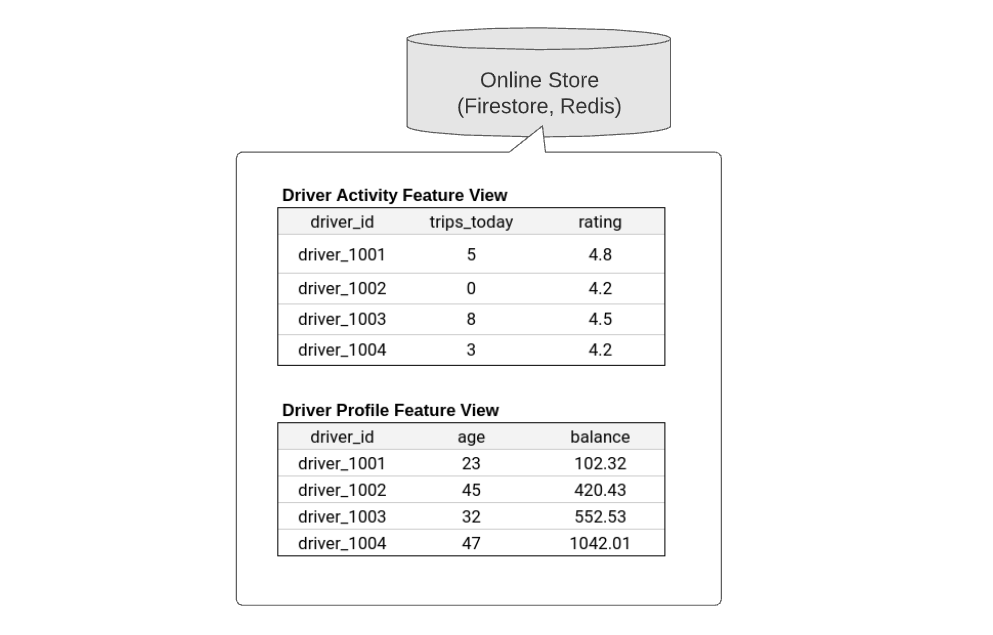
The storage schema of features within the online store mirrors that of the original data source. One key difference is that for each , only the latest feature values are stored. No historical values are stored.
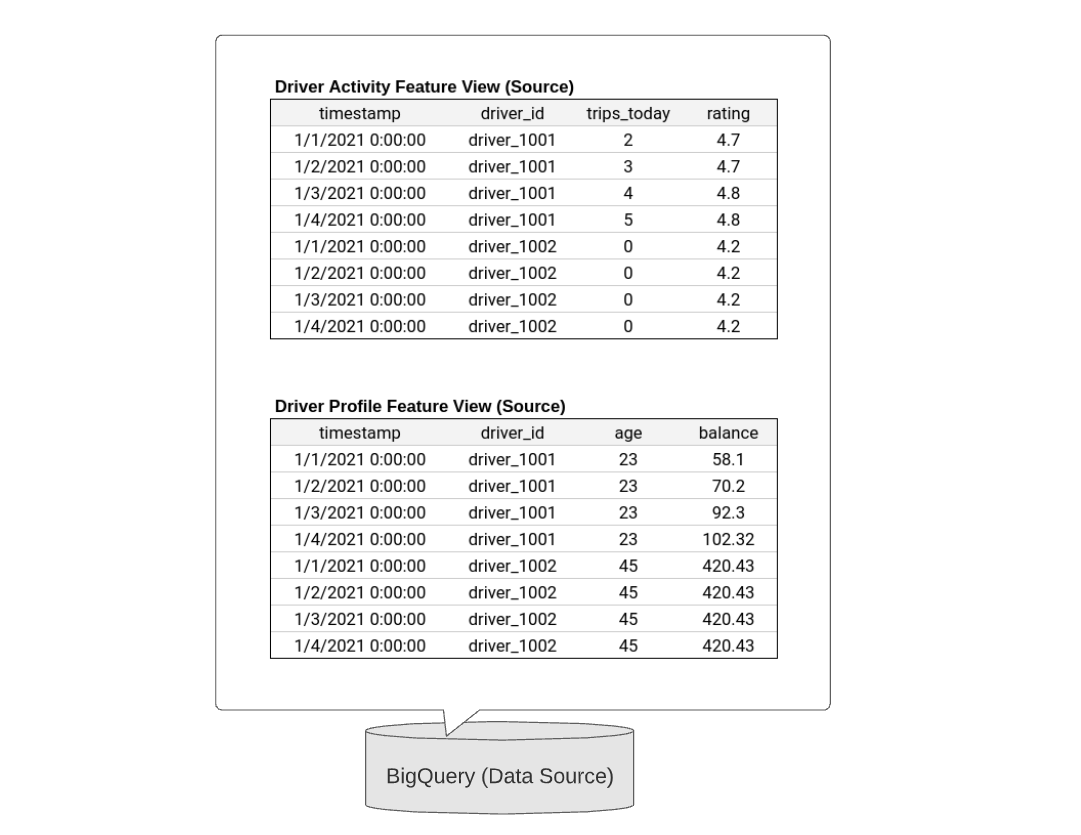
Here is an example batch data source:
Once the above data source is materialized into Feast (using feast materialize), the feature values will be stored as follows:
Registry
The Feast feature registry is a central catalog of all the feature definitions and their related metadata. It allows data scientists to search, discover, and collaborate on new features.
Each Feast deployment has a single feature registry. Feast only supports file-based registries today, but supports four different backends.
Local: Used as a local backend for storing the registry during development
The plugin must have some basic documentation on how it should be used.
The author must work with a maintainer to pass a basic code review (e.g. to ensure that the implementation roughly matches the core Feast implementations).
In order for a plugin integration to be merged into the main Feast repo, it must meet the following requirements:
The PR must pass all integration tests. The universal tests (tests specifically designed for custom integrations) must be updated to test the integration.
There is documentation and a tutorial on how to use the integration.
The author (or someone else) agrees to take ownership of all the files, and maintain those files going forward.
If the plugin is being contributed by an organization, and not an individual, the organization should provide the infrastructure (or credits) for integration tests.
Don't see your offline store or online store of choice here? Check out our guides to make a custom one!
The default Feast materialization process is an in-memory process, which pulls data from the offline store before writing it to the online store. However, this process does not scale for large data sets, since it's executed on a single-process.
Materializing (loading) features into an online store to serve those features at low-latency in a production setting.
Offline stores are configured through the feature_store.yaml. When building training datasets or materializing features into an online store, Feast will use the configured offline store with your configured data sources to execute the necessary data operations.
Only a single offline store can be used at a time. Moreover, offline stores are not compatible with all data sources; for example, the BigQuery offline store cannot be used to query a file-based data source.
Please see Push Source for more details on how to push features directly to the offline store in your feature store.
The Feast Python SDK allows users to retrieve feature values from an online store. This API is used to look up feature values at low latency during model serving in order to make online predictions.
Online stores only maintain the current state of features, i.e latest feature values. No historical data is stored or served.
Retrieving online features
1. Ensure that feature values have been loaded into the online store
Please ensure that you have materialized (loaded) your feature values into the online store before starting
Create a list of features that you would like to retrieve. This list typically comes from the model training step and should accompany the model binary.
3. Read online features
Next, we will create a feature store object and call get_online_features() which reads the relevant feature values directly from the online store.
If you need to clean up the infrastructure created by feast apply, use the teardown command.
****
Here we'll be using the example repository we created in the previous guide, Create a feature store. You can re-create it by running feast init in a new directory.
Deploying
At this point, no data has been materialized to your online store. Feast apply simply registers the feature definitions with Feast and spins up any necessary infrastructure such as tables. To load data into the online store, run feast materialize. See Load data into the online store for more details.
Warning: teardown is an irreversible command and will remove all feature store infrastructure. Proceed with caution!
For simplicity, Feast also provides a materialize command that will only ingest new data that has arrived in the offline store. Unlike materialize, materialize-incremental will track the state of previous ingestion runs inside of the feature registry.
The example command below will load only new data that has arrived for each feature view up to the end date and time (2021-04-08T00:00:00).
The materialize-incremental command functions similarly to materialize in that it loads data over a specific time range for all feature views (or the selected feature views) into the online store.
Unlike materialize, materialize-incremental automatically determines the start time from which to load features from batch sources of each feature view. The first time materialize-incremental is executed it will set the start time to the oldest timestamp of each data source, and the end time as the one provided by the user. For each run of materialize-incremental, the end timestamp will be tracked.
Subsequent runs of materialize-incremental will then set the start time to the end time of the previous run, thus only loading new data that has arrived into the online store. Note that the end time that is tracked for each run is at the feature view level, not globally for all feature views, i.e, different feature views may have different periods that have been materialized into the online store.
S3: Used as a centralized backend for storing the registry on AWS
GCS: Used as a centralized backend for storing the registry on GCP
[Alpha] Azure: Used as centralized backend for storing the registry on Azure Blob storage.
The feature registry is updated during different operations when using Feast. More specifically, objects within the registry (entities, feature views, feature services) are updated when running apply from the Feast CLI, but metadata about objects can also be updated during operations like materialization.
Users interact with a feature registry through the Feast SDK. Listing all feature views:
The feature registry is a of Feast metadata. This Protobuf file can be read programmatically from other programming languages, but no compatibility guarantees are made on the internal structure of the registry.
Overview
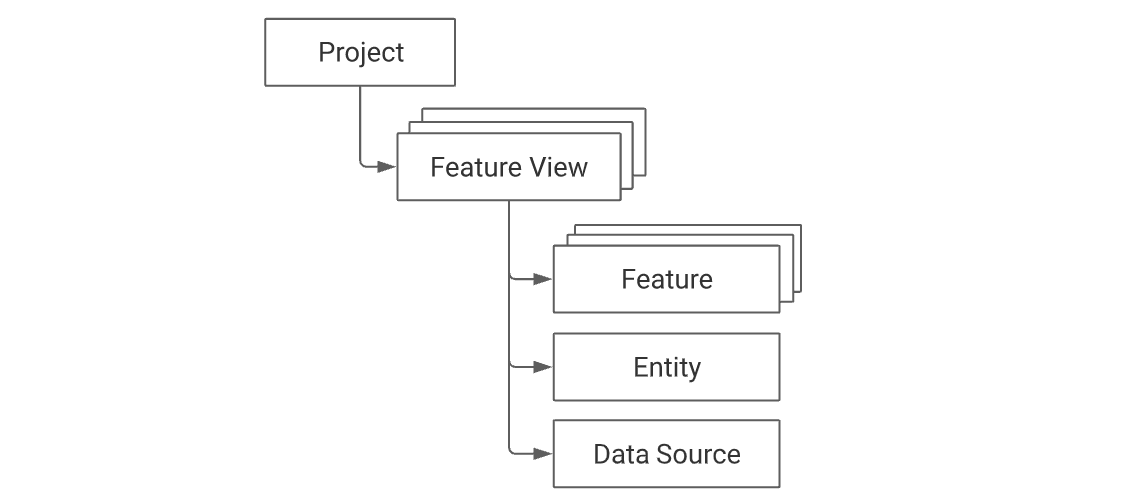
Feast project structure
The top-level namespace within Feast is a project. Users define one or more feature views within a project. Each feature view contains one or more features. These features typically relate to one or more entities. A feature view must always have a data source, which in turn is used during the generation of training datasets and when materializing feature values into the online store.
Projects provide complete isolation of feature stores at the infrastructure level. This is accomplished through resource namespacing, e.g., prefixing table names with the associated project. Each project should be considered a completely separate universe of entities and features. It is not possible to retrieve features from multiple projects in a single request. We recommend having a single feature store and a single project per environment (dev, staging, prod).
Data ingestion
For offline use cases that only rely on batch data, Feast does not need to ingest data and can query your existing data (leveraging a compute engine, whether it be a data warehouse or (experimental) Spark / Trino). Feast can help manage pushing streaming features to a batch source to make features available for training.
For online use cases, Feast supports ingesting features from batch sources to make them available online (through a process called materialization), and pushing streaming features to make them available both offline / online. We explore this more in the next concept page ()
Features are registered as code in a version controlled repository, and tie to data sources + model versions via the concepts of entities, feature views, and feature services. We explore these concepts more in the upcoming concept pages. These features are then stored in a registry, which can be accessed across users and services. The features can then be retrieved via SDK API methods or via a deployed feature server which exposes endpoints to query for online features (to power real time models).
Feast supports several patterns of feature retrieval.
Use case
Example
API
[Alpha] Saved dataset
Feast datasets allow for conveniently saving dataframes that include both features and entities to be subsequently used for data analysis and model training. Data Quality Monitoring was the primary motivation for creating dataset concept.
Dataset's metadata is stored in the Feast registry and raw data (features, entities, additional input keys and timestamp) is stored in the offline store.
Dataset can be created from:
Results of historical retrieval
[planned] Logging request (including input for ) and response during feature serving
[planned] Logging features during writing to online store (from batch source or stream)
To create a saved dataset from historical features for later retrieval or analysis, a user needs to call get_historical_features method first and then pass the returned retrieval job to create_saved_dataset method. create_saved_dataset will trigger the provided retrieval job (by calling .persist() on it) to store the data using the specified storage behind the scenes. Storage type must be the same as the globally configured offline store (e.g it's impossible to persist data to a different offline source). create_saved_dataset will also create a SavedDataset object with all of the related metadata and will write this object to the registry.
Saved dataset can be retrieved later using the get_saved_dataset method in the feature store:
Check out our to see how this concept can be applied in a real-world use case.
Entity
An entity is a collection of semantically related features. Users define entities to map to the domain of their use case. For example, a ride-hailing service could have customers and drivers as their entities, which group related features that correspond to these customers and drivers.
The entity name is used to uniquely identify the entity (for example to show in the experimental Web UI). The join key is used to identify the physical primary key on which feature values should be joined together to be retrieved during feature retrieval.
Entities are used by Feast in many contexts, as we explore below:
Use case #1: Defining and storing features
Feast's primary object for defining features is a feature view, which is a collection of features. Feature views map to 0 or more entities, since a feature can be associated with:
zero entities (e.g. a global feature like num_daily_global_transactions)
one entity (e.g. a user feature like user_age or last_5_bought_items)
multiple entities, aka a composite key (e.g. a user + merchant category feature like num_user_purchases_in_merchant_category)
Feast refers to this collection of entities for a feature view as an entity key.
Entities should be reused across feature views. This helps with discovery of features, since it enables data scientists understand how other teams build features for the entity they are most interested in.
Feast will use the feature view concept to then define the schema of groups of features in a low-latency online store.
At training time, users control what entities they want to look up, for example corresponding to train / test / validation splits. A user specifies a list of entity keys + timestamps they want to fetch correct features for to generate a training dataset.
At serving time, users specify entity key(s) to fetch the latest feature values which can power real-time model prediction (e.g. a fraud detection model that needs to fetch the latest transaction user's features to make a prediction).
Create a feature repository
A feature repository is a directory that contains the configuration of the feature store and individual features. This configuration is written as code (Python/YAML) and it's highly recommended that teams track it centrally using git. See Feature Repository for a detailed explanation of feature repositories.
The easiest way to create a new feature repository to use feast init command:
feast init
Creating a new Feast repository in /<...>/tiny_pika.
feastinit-tsnowflakeSnowflake
feast init -t gcp
Creating a new Feast repository in /<...>/tiny_pika.
feast init -t aws
AWS Region (e.g. us-west-2): ...
Redshift Cluster ID: ...
Redshift Database Name: ...
Redshift User Name: ...
Redshift S3 Staging Location (s3://*): ...
Redshift IAM Role for S3 (arn:aws:iam::*:role/*): ...
Should I upload example data to Redshift (overwriting 'feast_driver_hourly_stats' table)? (Y/n):
Creating a new Feast repository in /<...>/tiny_pika.
The init command creates a Python file with feature definitions, sample data, and a Feast configuration file for local development:
Enter the directory:
You can now use this feature repository for development. You can try the following:
Run feast apply to apply these definitions to Feast.
Edit the example feature definitions in example.py and run feast apply again to change feature definitions.
Structuring Feature Repos
A common scenario when using Feast in production is to want to test changes to Feast object definitions. For this, we recommend setting up a staging environment for your offline and online stores, which mirrors production (with potentially a smaller data set). Having this separate environment allows users to test changes by first applying them to staging, and then promoting the changes to production after verifying the changes on staging.
Setting up multiple environments
There are three common ways teams approach having separate environments
Have separate git branches for each environment
Have separate feature_store.yaml files and separate Feast object definitions that correspond to each environment
Have separate feature_store.yaml files per environment, but share the Feast object definitions
To keep a clear separation of the feature repos, teams may choose to have multiple long-lived branches in their version control system, one for each environment. In this approach, with CI/CD setup, changes would first be made to the staging branch, and then copied over manually to the production branch once verified in the staging environment.
For this approach, we have created an example repository () which contains two Feast projects, one per environment.
The contents of this repository are shown below:
The repository contains three sub-folders:
staging/: This folder contains the staging feature_store.yaml and Feast objects. Users that want to make changes to the Feast deployment in the staging environment will commit changes to this directory.
production/: This folder contains the production feature_store.yaml and Feast objects. Typically users would first test changes in staging before copying the feature definitions into the production folder, before committing the changes.
The feature_store.yaml contains the following:
Notice how the registry has been configured to use a Google Cloud Storage bucket. All changes made to infrastructure using feast apply are tracked in the registry.db. This registry will be accessed later by the Feast SDK in your training pipelines or model serving services in order to read features.
If your organization consists of many independent data science teams or a single group is working on several projects that could benefit from sharing features, entities, sources, and transformations, then we encourage you to utilize Python packages inside each environment:
This approach is very similar to the previous approach, but instead of having feast objects duplicated and having to copy over changes, it may be possible to share the same Feast object definitions and have different feature_store.yaml configuration.
An example of how such a repository would be structured is as follows:
Users can then apply the applying them to each environment in this way:
This setup has the advantage that you can share the feature definitions entirely, which may prevent issues with copy-pasting code.
In summary, once you have set up a Git based repository with CI that runs feast apply on changes, your infrastructure (offline store, online store, and cloud environment) will automatically be updated to support the loading of data into the feature store or retrieval of data.
Point-in-time joins
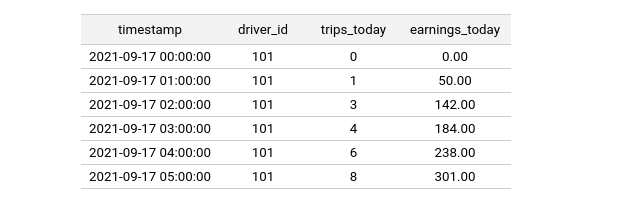
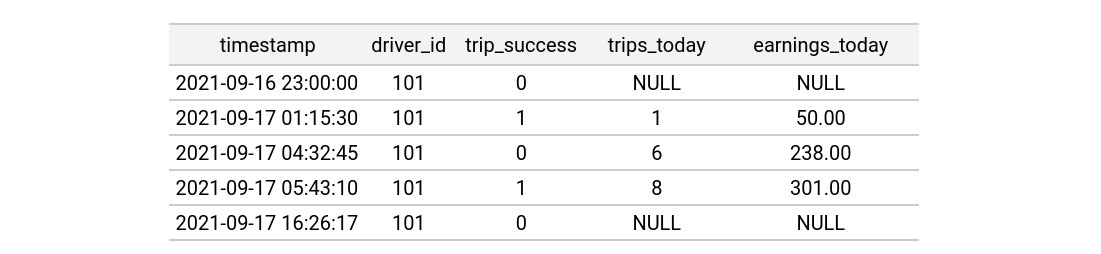
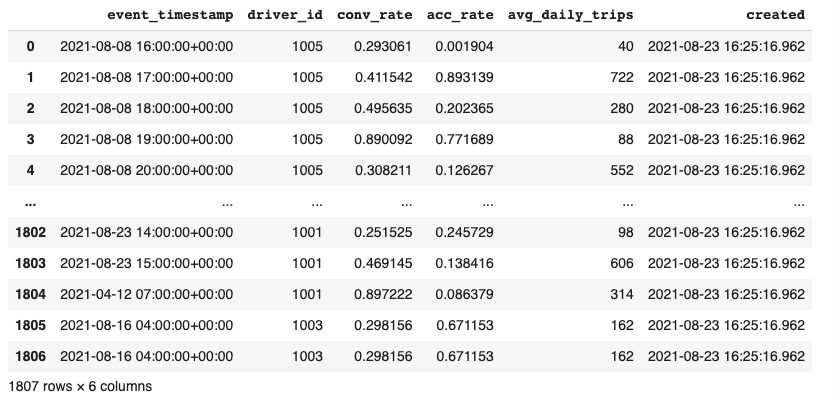
Feature values in Feast are modeled as time-series records. Below is an example of a driver feature view with two feature columns (trips_today, and earnings_today):
The above table can be registered with Feast through the following feature view:
Feast is able to join features from one or more feature views onto an entity dataframe in a point-in-time correct way. This means Feast is able to reproduce the state of features at a specific point in the past.
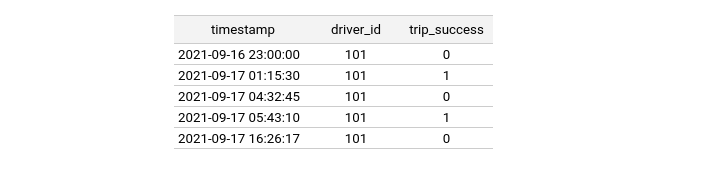
Given the following entity dataframe, imagine a user would like to join the above driver_hourly_stats feature view onto it, while preserving the trip_success column:
The timestamps within the entity dataframe above are the events at which we want to reproduce the state of the world (i.e., what the feature values were at those specific points in time). In order to do a point-in-time join, a user would load the entity dataframe and run historical retrieval:
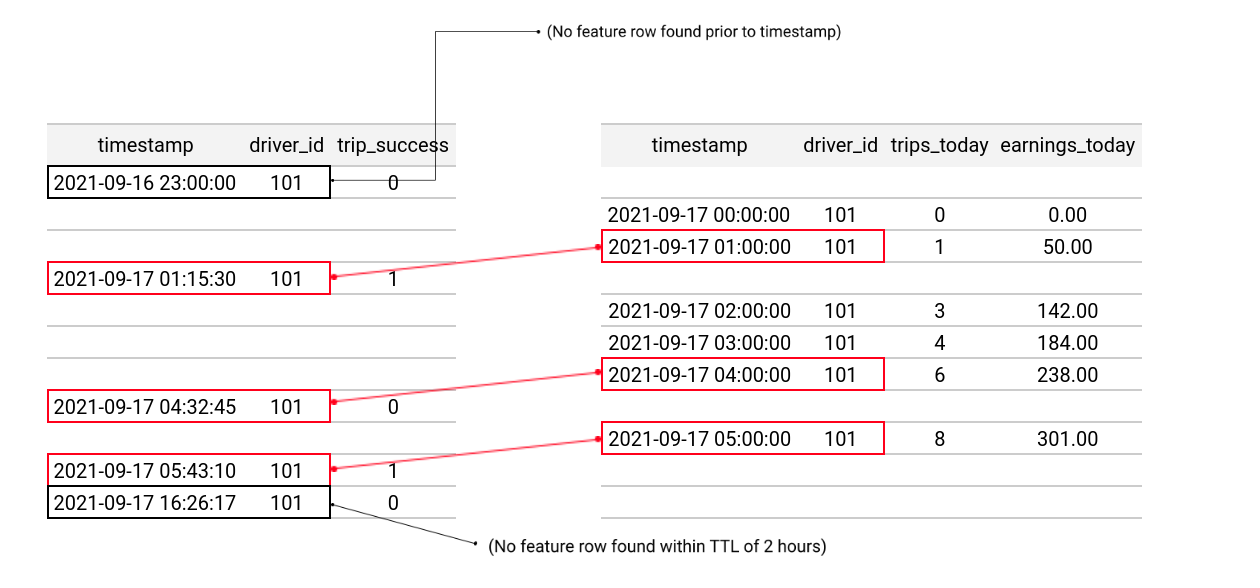
For each row within the entity dataframe, Feast will query and join the selected features from the appropriate feature view data source. Feast will scan backward in time from the entity dataframe timestamp up to a maximum of the TTL time specified.
Below is the resulting joined training dataframe. It contains both the original entity rows and joined feature values:
Three feature rows were successfully joined to the entity dataframe rows. The first row in the entity dataframe was older than the earliest feature rows in the feature view and could not be joined. The last row in the entity dataframe was outside of the TTL window (the event happened 11 hours after the feature row) and also couldn't be joined.
Type System
Motivation
Feast uses an internal type system to provide guarantees on training and serving data. Feast currently supports eight primitive types - INT32, INT64, FLOAT32, FLOAT64, STRING, BYTES, BOOL, and UNIX_TIMESTAMP - and the corresponding array types. Null types are not supported, although the UNIX_TIMESTAMP type is nullable. The type system is controlled by Value.proto in protobuf and by types.py in Python. Type conversion logic can be found in .
During feast apply, Feast runs schema inference on the data sources underlying feature views. For example, if the schema parameter is not specified for a feature view, Feast will examine the schema of the underlying data source to determine the event timestamp column, feature columns, and entity columns. Each of these columns must be associated with a Feast type, which requires conversion from the data source type system to the Feast type system.
The feature inference logic calls _infer_features_and_entities.
Feast serves feature values as proto objects, which have a type corresponding to Feast types. Thus Feast must materialize feature values into the online store as Value proto objects.
The local materialization engine first pulls the latest historical features and converts it to pyarrow.
Then it calls _convert_arrow_to_proto to convert the pyarrow table to proto format.
This calls python_values_to_proto_values in type_map.py
The Feast type system is typically not necessary when retrieving historical features. A call to get_historical_features will return a RetrievalJob object, which allows the user to export the results to one of several possible locations: a Pandas dataframe, a pyarrow table, a data lake (e.g. S3 or GCS), or the offline store (e.g. a Snowflake table). In all of these cases, the type conversion is handled natively by the offline store. For example, a BigQuery query exposes a to_dataframe method that will automatically convert the result to a dataframe, without requiring any conversions within Feast.
As mentioned above in the section on , Feast persists feature values into the online store as Value proto objects. A call to get_online_features will return an OnlineResponse object, which essentially wraps a bunch of Value protos with some metadata. The OnlineResponse object can then be converted into a Python dictionary, which calls feast_value_type_to_python_type from type_map.py, a utility that converts the Feast internal types to Python native types.
Spark (contrib)
Description
Spark data sources are tables or files that can be loaded from some Spark store (e.g. Hive or in-memory). They can also be specified by a SQL query.
Disclaimer
The Spark data source does not achieve full test coverage. Please do not assume complete stability.
Examples
Using a table reference from SparkSession (for example, either in-memory or a Hive Metastore):
The full set of configuration options is available here.
Supported Types
Spark data sources support all eight primitive types and their corresponding array types. For a comparison against other batch data sources, please see .
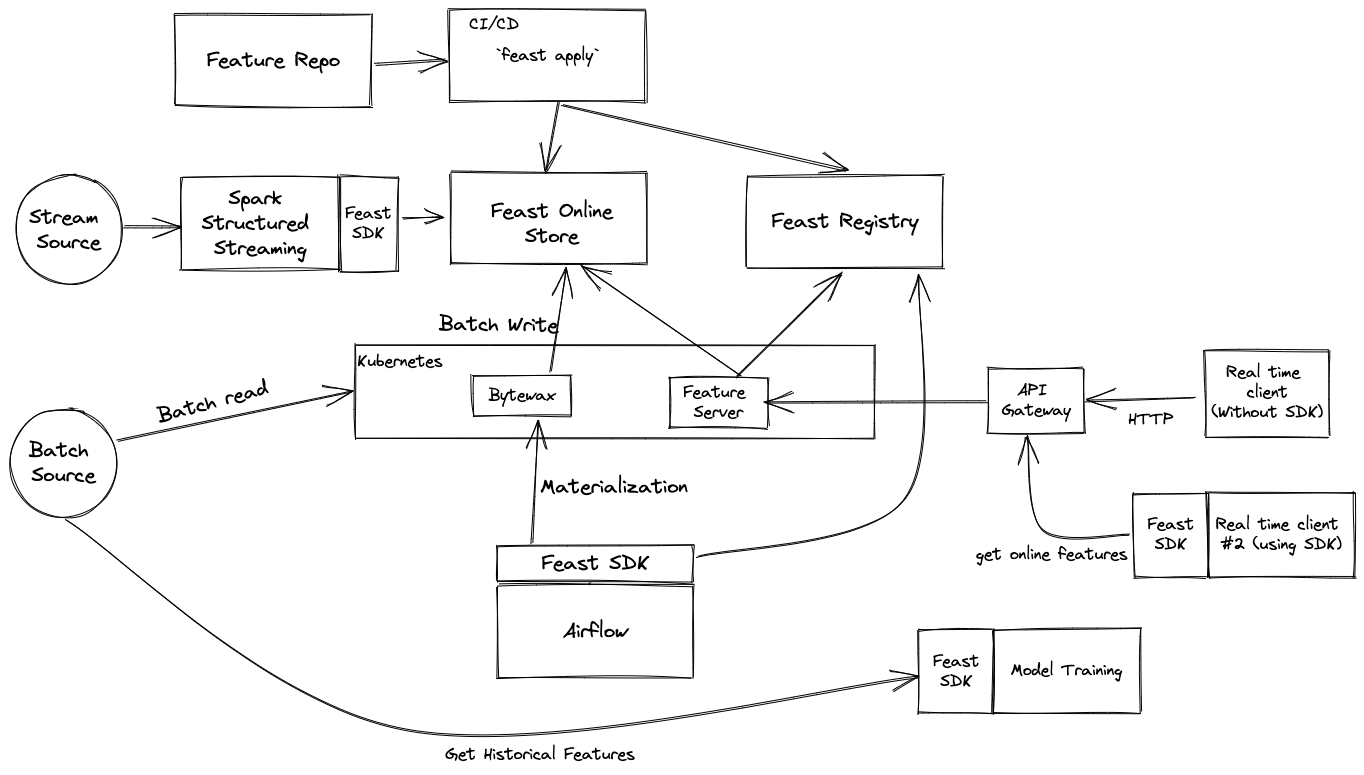
Overview
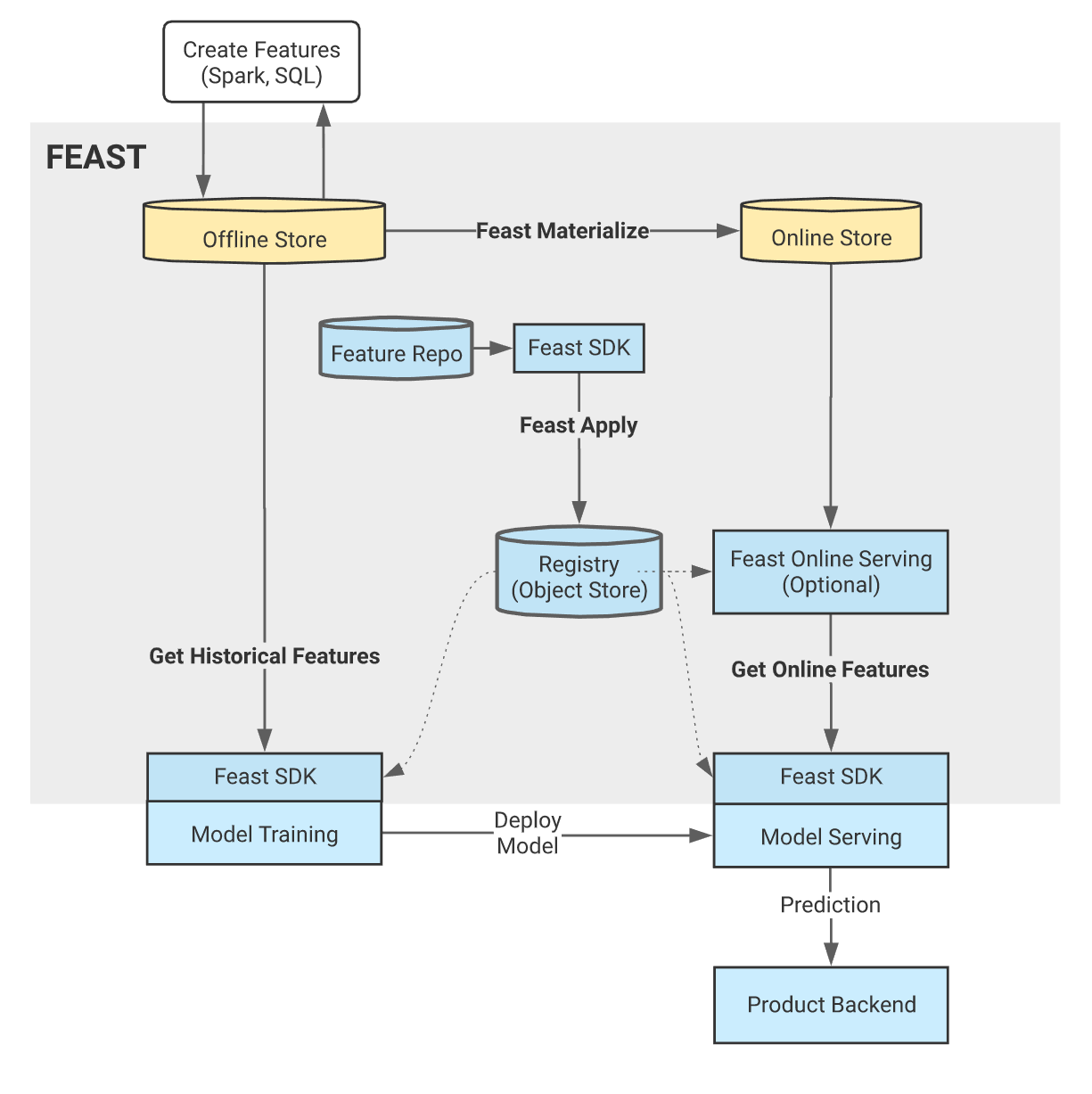
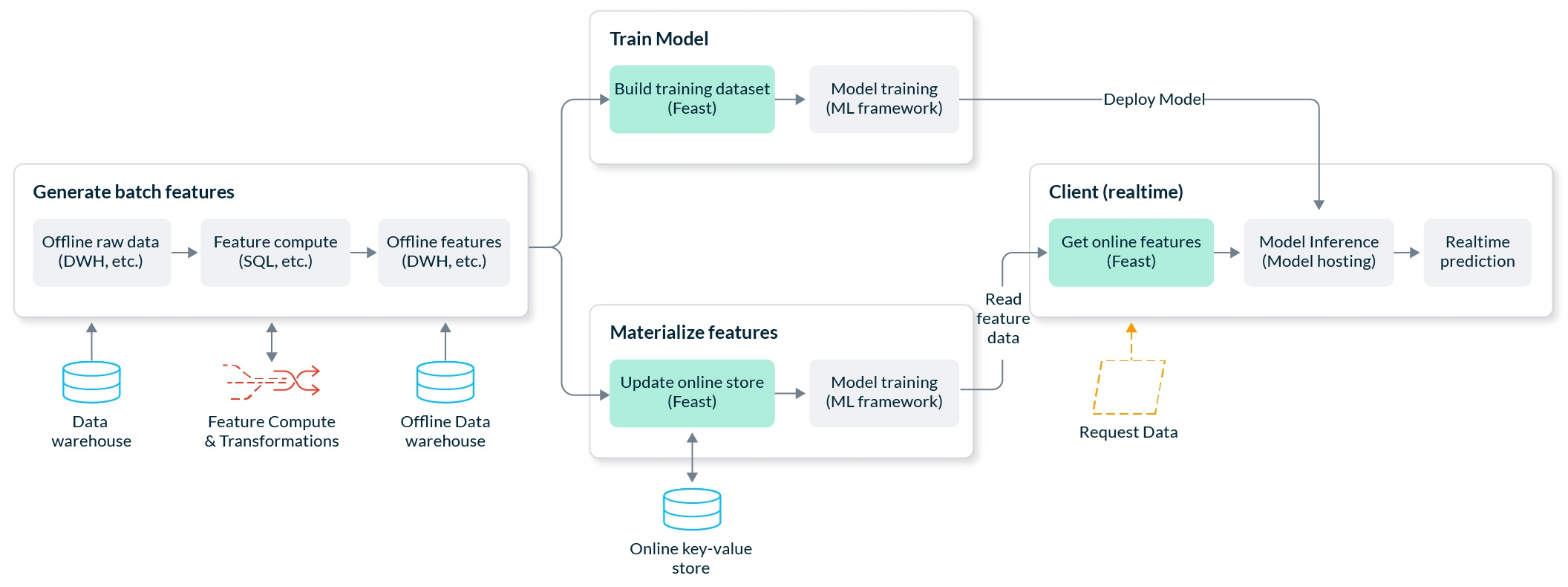
Feast Architecture Diagram
Functionality
Create Batch Features: ELT/ETL systems like Spark and SQL are used to transform data in the batch store.
Create Stream Features: Stream features are created from streaming services such as Kafka or Kinesis, and can be pushed directly into Feast via the Push API.
Feast Apply: The user (or CI) publishes versioned controlled feature definitions using feast apply. This CLI command updates infrastructure and persists definitions in the object store registry.
Feast Materialize: The user (or scheduler) executes feast materialize which loads features from the offline store into the online store.
Model Training: A model training pipeline is launched. It uses the Feast Python SDK to retrieve a training dataset that can be used for training models.
Get Historical Features: Feast exports a point-in-time correct training dataset based on the list of features and entity dataframe provided by the model training pipeline.
Deploy Model: The trained model binary (and list of features) are deployed into a model serving system. This step is not executed by Feast.
Prediction: A backend system makes a request for a prediction from the model serving service.
Get Online Features: The model serving service makes a request to the Feast Online Serving service for online features using a Feast SDK.
A complete Feast deployment contains the following components:
Feast Registry: An object store (GCS, S3) based registry used to persist feature definitions that are registered with the feature store. Systems can discover feature data by interacting with the registry through the Feast SDK.
Feast Python SDK/CLI: The primary user facing SDK. Used to:
Manage version controlled feature definitions.
Build a training dataset
Feast allows users to build a training dataset from time-series feature data that already exists in an offline store. Users are expected to provide a list of features to retrieve (which may span multiple feature views), and a dataframe to join the resulting features onto. Feast will then execute a point-in-time join of multiple feature views onto the provided dataframe, and return the full resulting dataframe.
Retrieving historical features
1. Register your feature views
Please ensure that you have created a feature repository and that you have registered (applied) your feature views with Feast.
Start by defining the feature references (e.g., driver_trips:average_daily_rides) for the features that you would like to retrieve from the offline store. These features can come from multiple feature tables. The only requirement is that the feature tables that make up the feature references have the same entity (or composite entity), and that they aren't located in the same offline store.
An entity dataframe is the target dataframe on which you would like to join feature values. The entity dataframe must contain a timestamp column called event_timestamp and all entities (primary keys) necessary to join feature tables onto. All entities found in feature views that are being joined onto the entity dataframe must be found as column on the entity dataframe.
It is possible to provide entity dataframes as either a Pandas dataframe or a SQL query.
Pandas:
In the example below we create a Pandas based entity dataframe that has a single row with an event_timestamp column and a driver_id entity column. Pandas based entity dataframes may need to be uploaded into an offline store, which may result in longer wait times compared to a SQL based entity dataframe.
SQL (Alternative):
Below is an example of an entity dataframe built from a BigQuery SQL query. It is only possible to use this query when all feature views being queried are available in the same offline store (BigQuery).
4. Launch historical retrieval
Once the feature references and an entity dataframe are defined, it is possible to call get_historical_features(). This method launches a job that executes a point-in-time join of features from the offline store onto the entity dataframe. Once completed, a job reference will be returned. This job reference can then be converted to a Pandas dataframe by calling to_df().
Snowflake
The batch materialization engine provides a highly scalable and parallel execution engine using a Snowflake Warehouse for batch materializations operations (materialize and materialize-incremental) when using a SnowflakeSource.
The engine requires no additional configuration other than for you to supply Snowflake's standard login and context details. The engine leverages custom (automatically deployed for you) Python UDFs to do the proper serialization of your offline store data to your online serving tables.
When using all three options together, snowflake.offline, snowflake.engine, and snowflake.online
Introduction
Feast (Feature Store) is a customizable operational data system that re-uses existing infrastructure to manage and serve machine learning features to realtime models.
Feast allows ML platform teams to:
Make features consistently available for training and serving by managing an offline store (to process historical data for scale-out batch scoring or model training), a low-latency online store (to power real-time prediction), and a battle-tested feature server (to serve pre-computed features online).
Azure
Offline Store: Uses the MsSql offline store by default. Also supports File as the offline store.
Online Store: Uses the Redis online store by default. Also supports Sqlite as an online store.
The Azure provider does not achieve full test coverage. Please do not assume complete stability.
In order to use this offline store, you'll need to run pip install 'feast[azure]'
source_datatype_to_feast_value_type cals the appropriate method in type_map.py. For example, if a SnowflakeSource is being examined, snowflake_python_type_to_feast_value_type from type_map.py will be called.
Initialize a git repository in the same directory and checking the feature repository into version control.
Deployment
URL:
...
SnowflakeUserName:...
SnowflakePassword:...
SnowflakeRoleName:...
SnowflakeWarehouseName:...
SnowflakeDatabaseName:...
CreatinganewFeastrepositoryin/<...>/tiny_pika.
.github: This folder is an example of a CI system that applies the changes in either the staging or production repositories using feast apply. This operation saves your feature definitions to a shared registry (for example, on GCS) and configures your infrastructure for serving features.
Different version control branches
Separate feature_store.yaml files and separate Feast object definitions
It is important to note that the CI system above must have access to create, modify, or remove infrastructure in your production environment. This is unlike clients of the feature store, who will only have read access.
Shared Feast Object definitions with separate feature_store.yaml files
The AWS Lambda batch materialization engine is considered alpha status. It relies on the offline store to output feature values to S3 via to_remote_storage, and then loads them into the online store.
Materialize (load) feature values into the online store.
Build and retrieve training datasets from the offline store.
Retrieve online features.
Stream Processor: The Stream Processor can be used to ingest feature data from streams and write it into the online or offline stores. Currently, there's an experimental Spark processor that's able to consume data from Kafka.
Batch Materialization Engine: The Batch Materialization Engine component launches a process which loads data into the online store from the offline store. By default, Feast uses a local in-process engine implementation to materialize data. However, additional infrastructure can be used for a more scalable materialization process.
Online Store: The online store is a database that stores only the latest feature values for each entity. The online store is either populated through materialization jobs or through stream ingestion.
Offline Store: The offline store persists batch data that has been ingested into Feast. This data is used for producing training datasets. For feature retrieval and materialization, Feast does not manage the offline store directly, but runs queries against it. However, offline stores can be configured to support writes if Feast configures logging functionality of served features.
Components
Java and Go Clients are also available for online feature retrieval.
Avoid data leakage by generating point-in-time correct feature sets so data scientists can focus on feature engineering rather than debugging error-prone dataset joining logic. This ensure that future feature values do not leak to models during training.
Decouple ML from data infrastructure by providing a single data access layer that abstracts feature storage from feature retrieval, ensuring models remain portable as you move from training models to serving models, from batch models to realtime models, and from one data infra system to another.
Feast helps ML platform teams with DevOps experience productionize real-time models. Feast can also help these teams build towards a feature platform that improves collaboration between engineers and data scientists.
Feast is likely not the right tool if you
are in an organization that’s just getting started with ML and is not yet sure what the business impact of ML is
rely primarily on unstructured data
need very low latency feature retrieval (e.g. p99 feature retrieval << 10ms)
have a small team to support a large number of use cases
anETL / ELTsystem: Feast is not (and does not plan to become) a general purpose data transformation or pipelining system. Users often leverage tools like dbt to manage upstream data transformations.
a data orchestration tool: Feast does not manage or orchestrate complex workflow DAGs. It relies on upstream data pipelines to produce feature values and integrations with tools like Airflow to make features consistently available.
a data warehouse: Feast is not a replacement for your data warehouse or the source of truth for all transformed data in your organization. Rather, Feast is a light-weight downstream layer that can serve data from an existing data warehouse (or other data sources) to models in production.
a database: Feast is not a database, but helps manage data stored in other systems (e.g. BigQuery, Snowflake, DynamoDB, Redis) to make features consistently available at training / serving time
reproducible model training / model backtesting / experiment management: Feast captures feature and model metadata, but does not version-control datasets / labels or manage train / test splits. Other tools like DVC, MLflow, and Kubeflow are better suited for this.
batch + streaming feature engineering: Feast primarily processes already transformed feature values (though it offers experimental light-weight transformations). Users usually integrate Feast with upstream systems (e.g. existing ETL/ELT pipelines). Tecton is a more fully featured feature platform which addresses these needs.
native streaming feature integration: Feast enables users to push streaming features, but does not pull from streaming sources or manage streaming pipelines. is a more fully featured feature platform which orchestrates end to end streaming pipelines.
feature sharing: Feast has experimental functionality to enable discovery and cataloguing of feature metadata with a . Feast also has community contributed plugins with and . also more robustly addresses these needs.
lineage: Feast helps tie feature values to model versions, but is not a complete solution for capturing end-to-end lineage from raw data sources to model versions. Feast also has community contributed plugins with and . captures more end-to-end lineage by also managing feature transformations.
data quality / drift detection: Feast has experimental integrations with , but is not purpose built to solve data drift / data quality issues. This requires more sophisticated monitoring across data pipelines, served feature values, labels, and model versions.
Many companies have used Feast to power real-world ML use cases such as:
Personalizing online recommendations by leveraging pre-computed historical user or item features.
Online fraud detection, using features that compare against (pre-computed) historical transaction patterns
Churn prediction (an offline model), generating feature values for all users at a fixed cadence in batch
Credit scoring, using pre-computed historical features to compute probability of default
Explore the following resources to get started with Feast:
Quickstart is the fastest way to get started with Feast
Concepts describes all important Feast API concepts
The best way to learn Feast is to use it. Head over to our and try it out!
# Read in entity dataframe
entity_df = pd.read_csv("entity_df.csv")
training_df = store.get_historical_features(
entity_df=entity_df,
features = [
'driver_hourly_stats:trips_today',
'driver_hourly_stats:earnings_today'
],
)
Please note that the TTL time is relative to each timestamp within the entity dataframe. TTL is not relative to the current point in time (when you run the query).
Entity dataframe containing timestamps, driver ids, and the target variable
Use case #2: Retrieving features
Q: Can I retrieve features for all entities?
Kind of.
In practice, this is most relevant for batch scoring models (e.g. predict user churn for all existing users) that are offline only. For these use cases, Feast supports generating features for a SQL-backed list of entities. There is an open GitHub issue that welcomes contribution to make this a more intuitive API.
For real-time feature retrieval, there is no out of the box support for this because it would promote expensive and slow scan operations which can affect the performance of other operations on your data sources. Users can still pass in a large list of entities for retrieval, but this does not scale well.
Feast uses a registry to store all applied Feast objects (e.g. Feature views, entities, etc). The registry exposes methods to apply, list, retrieve and delete these objects, and is an abstraction with multiple implementations.
Options for registry implementations
File-based registry
By default, Feast uses a file-based registry implementation, which stores the protobuf representation of the registry as a serialized file. This registry file can be stored in a local file system, or in cloud storage (in, say, S3 or GCS, or Azure).
The quickstart guides that use feast init will use a registry on a local file system. To allow Feast to configure a remote file registry, you need to create a GCS / S3 bucket that Feast can understand:
project:feast_demo_awsprovider:aws
project:feast_demo_gcpprovider:gcp
However, there are inherent limitations with a file-based registry, since changing a single field in the registry requires re-writing the whole registry file. With multiple concurrent writers, this presents a risk of data loss, or bottlenecks writes to the registry since all changes have to be serialized (e.g. when running materialization for multiple feature views or time ranges concurrently).
Alternatively, a can be used for a more scalable registry.
The configuration roughly looks like:
This supports any SQLAlchemy compatible database as a backend. The exact schema can be seen in
We recommend users store their Feast feature definitions in a version controlled repository, which then via CI/CD automatically stays synced with the registry. Users will often also want multiple registries to correspond to different environments (e.g. dev vs staging vs prod), with staging and production registries with locked down write access since they can impact real user traffic. See for details on how to set this up.
Users can specify the registry through a feature_store.yaml config file, or programmatically. We often see teams preferring the programmatic approach because it makes notebook driven development very easy:
Instantiating a FeatureStore object can then point to this:
Upgrading for Feast 0.20+
Overview
Starting with Feast 0.20, the APIs of many core objects (e.g. feature views and entities) have been changed. For example, many parameters have been renamed. These changes were made in a backwards-compatible fashion; existing Feast repositories will continue to work until Feast 0.23, without any changes required. However, Feast 0.24 will fully deprecate all of the old parameters, so in order to use Feast 0.24+ users must modify their Feast repositories.
There are currently deprecation warnings that indicate to users exactly how to modify their repos. In order to make the process somewhat easier, Feast 0.23 also introduces a new CLI command, repo-upgrade, that will partially automate the process of upgrading Feast repositories.
The upgrade command aims to automatically modify the object definitions in a feature repo to match the API required by Feast 0.24+. When running the command, the Feast CLI analyzes the source code in the feature repo files using bowler, and attempted to rewrite the files in a best-effort way. It's possible for there to be parts of the API that are not upgraded automatically.
The repo-upgrade command is specifically meant for upgrading Feast repositories that were initially created in versions 0.23 and below to be compatible with versions 0.24 and above. It is not intended to work for any future upgrades.
At the root of a feature repo, you can run feast repo-upgrade. By default, the CLI only echos the changes it's planning on making, and does not modify any files in place. If the changes look reasonably, you can specify the --write flag to have the changes be written out to disk.
An example:
To write these changes out, you can run the same command with the --write flag:
You should see the same output, but also see the changes reflected in your feature repo on disk.
Kafka
Warning: This is an experimental feature. It's intended for early testing and feedback, and could change without warnings in future releases.
Description
Kafka sources allow users to register Kafka streams as data sources. Feast currently does not launch or monitor jobs to ingest data from Kafka. Users are responsible for launching and monitoring their own ingestion jobs, which should write feature values to the online store through FeatureStore.write_to_online_store. An example of how to launch such a job with Spark can be found here. Feast also provides functionality to write to the offline store using the write_to_offline_store functionality.
Kafka sources must have a batch source specified. The batch source will be used for retrieving historical features. Thus users are also responsible for writing data from their Kafka streams to a batch data source such as a data warehouse table. When using a Kafka source as a stream source in the definition of a feature view, a batch source doesn't need to be specified in the feature view definition explicitly.
Stream sources
Streaming data sources are important sources of feature values. A typical setup with streaming data looks like:
Raw events come in (stream 1)
Streaming transformations applied (e.g. generating features like last_N_purchased_categories) (stream 2)
Write stream 2 values to an offline store as a historical log for training (optional)
Note that the Kafka source has a batch source.
The Kafka source can be used in a stream feature view.
See for a example of how to ingest data from a Kafka source into Feast.
Kinesis
Warning: This is an experimental feature. It's intended for early testing and feedback, and could change without warnings in future releases.
Description
Kinesis sources allow users to register Kinesis streams as data sources. Feast currently does not launch or monitor jobs to ingest data from Kinesis. Users are responsible for launching and monitoring their own ingestion jobs, which should write feature values to the online store through FeatureStore.write_to_online_store. An example of how to launch such a job with Spark to ingest from Kafka can be found here; by using a different plugin, the example can be adapted to Kinesis. Feast also provides functionality to write to the offline store using the write_to_offline_store functionality.
Kinesis sources must have a batch source specified. The batch source will be used for retrieving historical features. Thus users are also responsible for writing data from their Kinesis streams to a batch data source such as a data warehouse table. When using a Kinesis source as a stream source in the definition of a feature view, a batch source doesn't need to be specified in the feature view definition explicitly.
Stream sources
Streaming data sources are important sources of feature values. A typical setup with streaming data looks like:
Raw events come in (stream 1)
Streaming transformations applied (e.g. generating features like last_N_purchased_categories) (stream 2)
Write stream 2 values to an offline store as a historical log for training (optional)
Note that the Kinesis source has a batch source.
The Kinesis source can be used in a stream feature view.
See for a example of how to ingest data from a Kafka source into Feast. The approach used in the tutorial can be easily adapted to work for Kinesis as well.
Push
Description
Push sources allow feature values to be pushed to the online store and offline store in real time. This allows fresh feature values to be made available to applications. Push sources supercede the FeatureStore.write_to_online_store.
Push sources can be used by multiple feature views. When data is pushed to a push source, Feast propagates the feature values to all the consuming feature views.
Push sources must have a batch source specified. The batch source will be used for retrieving historical features. Thus users are also responsible for pushing data to a batch data source such as a data warehouse table. When using a push source as a stream source in the definition of a feature view, a batch source doesn't need to be specified in the feature view definition explicitly.
Stream sources
Streaming data sources are important sources of feature values. A typical setup with streaming data looks like:
Raw events come in (stream 1)
Streaming transformations applied (e.g. generating features like last_N_purchased_categories) (stream 2)
Write stream 2 values to an offline store as a historical log for training (optional)
Write stream 2 values to an online store for low latency feature serving
Periodically materialize feature values from the offline store into the online store for decreased training-serving skew and improved model performance
Feast allows users to push features previously registered in a feature view to the online store for fresher features. It also allows users to push batches of stream data to the offline store by specifying that the push be directed to the offline store. This will push the data to the offline store declared in the repository configuration used to initialize the feature store.
Note that the push schema needs to also include the entity.
Note that the to parameter is optional and defaults to online but we can specify these options: PushMode.ONLINE, PushMode.OFFLINE, or PushMode.ONLINE_AND_OFFLINE.
See also for instructions on how to push data to a deployed feature server.
The default option to write features from a stream is to add the Python SDK into your existing PySpark pipeline.
This can also be used under the hood by a contrib stream processor (see )
File
Description
The file offline store provides support for reading FileSources. It uses Dask as the compute engine.
All data is downloaded and joined using Python and therefore may not scale to production workloads.
Example
feature_store.yaml
project: my_feature_repo
registry: data/registry.db
provider: local
offline_store:
type: file
The set of functionality supported by offline stores is described in detail here. Below is a matrix indicating which functionality is supported by the file offline store.
File
Below is a matrix indicating which functionality is supported by FileRetrievalJob.
File
To compare this set of functionality against other offline stores, please see the full .
SQLite
Description
The SQLite online store provides support for materializing feature values into an SQLite database for serving online features.
All feature values are stored in an on-disk SQLite database
The set of functionality supported by online stores is described in detail . Below is a matrix indicating which functionality is supported by the Sqlite online store.
Sqlite
To compare this set of functionality against other online stores, please see the full .
Datastore
Description
The Datastore online store provides support for materializing feature values into Cloud Datastore. The data model used to store feature values in Datastore is described in more detail here.
Getting started
In order to use this online store, you'll need to run pip install 'feast[gcp]'. You can then get started with the command feast init REPO_NAME -t gcp.
The set of functionality supported by online stores is described in detail here. Below is a matrix indicating which functionality is supported by the Datastore online store.
Datastore
To compare this set of functionality against other online stores, please see the full .
Bigtable
Description
The Bigtable online store provides support for materializing feature values into Cloud Bigtable. The data model used to store feature values in Bigtable is described in more detail here.
Getting started
In order to use this online store, you'll need to run pip install 'feast[gcp]'. You can then get started with the command feast init REPO_NAME -t gcp.
The set of functionality supported by online stores is described in detail here. Below is a matrix indicating which functionality is supported by the Bigtable online store.
Bigtable
To compare this set of functionality against other online stores, please see the full .
MySQL (contrib)
Description
The MySQL online store provides support for materializing feature values into a MySQL database for serving online features.
Only the latest feature values are persisted
Getting started
In order to use this online store, you'll need to run pip install 'feast[mysql]'. You can get started by then running feast init and then setting the feature_store.yaml as described below.
Example
feature_store.yaml
project: my_feature_repo
registry: data/registry.db
provider: local
online_store:
type: mysql
host: DB_HOST
port: DB_PORT
database: DB_NAME
user: DB_USERNAME
password: DB_PASSWORD
The full set of configuration options is available in .
The set of functionality supported by online stores is described in detail . Below is a matrix indicating which functionality is supported by the Mys online store.
Mys
To compare this set of functionality against other online stores, please see the full .
Rockset (contrib)
Description
In Alpha Development.
The Rockset online store provides support for materializing feature values within a Rockset collection in order to serve features in real-time.
Each document is uniquely identified by its '_id' value. Repeated inserts into the same document '_id' will result in an upsert.
Rockset indexes all columns allowing for quick per feature look up and also allows for a dynamic typed schema that can change based on any new requirements. API Keys can be found in the Rockset console. You can also find host urls on the same tab by clicking "View Region Endpoint Urls".
Data Model Used Per Doc
Amazon Web Services
Description
Offline Store: Uses the Redshift offline store by default. Also supports File as the offline store.
Online Store: Uses the DynamoDB online store by default. Also supports Sqlite as an online store.
Getting started
In order to use this offline store, you'll need to run (Snowflake) pip install 'feast[aws, snowflake]' or (Redshift) pip install 'feast[aws]'.
You can get started by then running feast init -t snowflake or feast init -t aws.
Adding a custom batch materialization engine
Feast batch materialization operations (materialize and materialize-incremental) execute through a BatchMaterializationEngine.
Custom batch materialization engines allow Feast users to extend Feast to customize the materialization process. Examples include:
Setting up custom materialization-specific infrastructure during feast apply (e.g. setting up Spark clusters or Lambda Functions)
Data ingestion
A data source in Feast refers to raw underlying data that users own (e.g. in a table in BigQuery). Feast does not manage any of the raw underlying data but instead, is in charge of loading this data and performing different operations on the data to retrieve or serve features.
Feast uses a time-series data model to represent data. This data model is used to interpret feature data in data sources in order to build training datasets or materialize features into an online store.
Below is an example data source with a single entity column (driver) and two feature columns (trips_today, and rating).
Feast supports primarily time-stamped
Driver stats on Snowflake
Initial demonstration of Snowflake as an offline+online store with Feast, using the Snowflake demo template.
In the steps below, we will set up a sample Feast project that leverages Snowflake as an offline store + materialization engine + online store.
Starting with data in a Snowflake table, we will register that table to the feature store and define features associated with the columns in that table. From there, we will generate historical training data based on those feature definitions and then materialize the latest feature values into the online store. Lastly, we will retrieve the materialized feature values.
Our template will generate new data containing driver statistics. From there, we will show you code snippets that will call to the offline store for generating training datasets, and then the code for calling the online store to serve you the latest feature values to serve models in production.
The following files will automatically be created in your project folder:
Using Scalable Registry
Tutorial on how to use the SQL registry for scalable registry updates
By default, the registry Feast uses a file-based registry implementation, which stores the protobuf representation of the registry as a serialized file. This registry file can be stored in a local file system, or in cloud storage (in, say, S3 or GCS).
However, there's inherent limitations with a file-based registry, since changing a single field in the registry requires re-writing the whole registry file. With multiple concurrent writers, this presents a risk of data loss, or bottlenecks writes to the registry since all changes have to be serialized (e.g. when running materialization for multiple feature views or time ranges concurrently).
An alternative to the file-based registry is the which ships with Feast. This implementation stores the registry in a relational database, and allows for changes to individual objects atomically. Under the hood, the SQL Registry implementation uses to abstract over the different databases. Consequently, any by SQLAlchemy can be used by the SQL Registry. The following databases are supported and tested out of the box:
Snowflake
The offline store provides support for reading .
All joins happen within Snowflake.
Entity dataframes can be provided as a SQL query or can be provided as a Pandas dataframe. A Pandas dataframes will be uploaded to Snowflake as a temporary table in order to complete join operations.
In order to use this offline store, you'll need to run pip install 'feast[snowflake]'
BigQuery
The BigQuery offline store provides support for reading .
All joins happen within BigQuery.
Entity dataframes can be provided as a SQL query or can be provided as a Pandas dataframe. A Pandas dataframes will be uploaded to BigQuery as a table (marked for expiration) in order to complete join operations.
In order to use this offline store, you'll need to run pip install 'feast[gcp]'
Spark (contrib)
The Spark offline store provides support for reading .
Entity dataframes can be provided as a SQL query or can be provided as a Pandas dataframe. A Pandas dataframes will be converted to a Spark dataframe and processed as a temporary view.
The Spark offline store does not achieve full test coverage. Please do not assume complete stability.
In order to use this offline store, you'll need to run pip install 'feast[spark]'. You can get started by then running feast init -t spark
PostgreSQL (contrib)
The PostgreSQL offline store provides support for reading .
Entity dataframes can be provided as a SQL query or can be provided as a Pandas dataframe. A Pandas dataframes will be uploaded to Postgres as a table in order to complete join operations.
The PostgreSQL offline store does not achieve full test coverage. Please do not assume complete stability.
In order to use this offline store, you'll need to run pip install 'feast[postgres]'. You can get started by then running feast init -t postgres
Azure Synapse + Azure SQL (contrib)
The MsSQL offline store provides support for reading . Specifically, it is developed to read from on Microsoft Azure
Entity dataframes can be provided as a SQL query or can be provided as a Pandas dataframe.
In order to use this offline store, you'll need to run pip install 'feast[azure]'. You can get started by then following this .
The MsSQL offline store does not achieve full test coverage. Please do not assume complete stability.
PostgreSQL (contrib)
The PostgreSQL online store provides support for materializing feature values into a PostgreSQL database for serving online features.
Only the latest feature values are persisted
sslmode, sslkey_path, sslcert_path, and sslrootcert_path are optional
In order to use this online store, you'll need to run pip install 'feast[postgres]'
Hazelcast (contrib)
Hazelcast online store is in alpha development.
The online store provides support for materializing feature values into a Hazelcast cluster for serving online features in real-time. In order to use Hazelcast as online store, you need to have a running Hazelcast cluster. You can create a cluster using Hazelcast Viridian Serverless. See this page for more details.
Each feature view is mapped one-to-one to a specific Hazelcast IMap
Spark (contrib)
The Spark batch materialization engine is considered alpha status. It relies on the offline store to output feature values to S3 via to_remote_storage, and then loads them into the online store.
See for configuration options.
teardown infrastructure (e.g. tables) in the online store
yes
generate a plan of infrastructure changes
no
support for on-demand transforms
yes
readable by Python SDK
yes
readable by Java
no
readable by Go
no
support for entityless feature views
yes
support for concurrent writing to the same key
no
support for ttl (time to live) at retrieval
no
support for deleting expired data
no
collocated by feature view
yes
collocated by feature service
no
collocated by entity key
no
write feature values to the online store
yes
read feature values from the online store
yes
update infrastructure (e.g. tables) in the online store
Write stream 2 values to an online store for low latency feature serving
Periodically materialize feature values from the offline store into the online store for decreased training-serving skew and improved model performance
Write stream 2 values to an online store for low latency feature serving
Periodically materialize feature values from the offline store into the online store for decreased training-serving skew and improved model performance
Launching custom batch ingestion (materialization) jobs (Spark, Beam, AWS Lambda)
Tearing down custom materialization-specific infrastructure during feast teardown (e.g. tearing down Spark clusters, or deleting Lambda Functions)
Feast comes with built-in materialization engines, e.g, LocalMaterializationEngine, and an experimental LambdaMaterializationEngine. However, users can develop their own materialization engines by creating a class that implements the contract in the BatchMaterializationEngine class.
The fastest way to add custom logic to Feast is to extend an existing materialization engine. The most generic engine is the LocalMaterializationEngine which contains no cloud-specific logic. The guide that follows will extend the LocalProvider with operations that print text to the console. It is up to you as a developer to add your custom code to the engine methods, but the guide below will provide the necessary scaffolding to get you started.
The first step is to define a custom materialization engine class. We've created the MyCustomEngine below.
Notice how in the above engine we have only overwritten two of the methods on the LocalMaterializatinEngine, namely update and materialize. These two methods are convenient to replace if you are planning to launch custom batch jobs.
Configure your feature_store.yaml file to point to your new engine class:
Notice how the batch_engine field above points to the module and class where your engine can be found.
Now you should be able to use your engine by running a Feast command:
It may also be necessary to add the module root path to your PYTHONPATH as follows:
That's it. You should now have a fully functional custom engine!
Overview
Guide
Step 1: Define an Engine class
Step 2: Configuring Feast to use the engine
Step 3: Using the engine
feature_store.yaml -- This is your main configuration file
driver_repo.py -- This is your main feature definition file
test.py -- This is a file to test your feature store configuration
Here you will see the information that you entered. This template will use Snowflake as the offline store, materialization engine, and the online store. The main thing to remember is by default, Snowflake objects have ALL CAPS names unless lower case was specified.
Create a dummy training dataframe, then call our offline store to add additional columns
Materialize the latest feature values into our online store
Retrieve the latest values from our online store based on our entity key
PostgreSQL
MySQL
Sqlite
Feast can use the SQL Registry via a config change in the feature_store.yaml file. An example of how to configure this would be:
Specifically, the registry_type needs to be set to sql in the registry config block. On doing so, the path should refer to the Database URL for the database to be used, as expected by SQLAlchemy. No other additional commands are currently needed to configure this registry.
Should you choose to use a database technology that is compatible with one of Feast's supported registry backends, but which speaks a different dialect (e.g. cockroachdb, which is compatible with postgres) then some further intervention may be required on your part.
SQLAlchemy, used by the registry, may not be able to detect your database version without first updating your DSN scheme to the appropriate DBAPI/dialect combination. When this happens, your database is likely using what is referred to as an external dialect in SQLAlchemy terminology. See your database's documentation for examples on how to set its scheme in the Database URL.
Psycopg2, which is the database library leveraged by the online and offline stores, is not impacted by the need to speak a particular dialect, and so the following only applies to the registry.
If you are not running Feast in a container, to accomodate SQLAlchemy's need to speak an external dialect, install additional Python modules like we do as follows using cockroachdb for example:
If you are running Feast in a container, you will need to create a custom image like we do as follows, again using cockroachdb as an example:
If you are running Feast in Kubernetes, set the image.repository and imagePullSecrets Helm values accordingly to utilize your custom image.
There are some things to note about how the SQL registry works:
Once instantiated, the Registry ensures the tables needed to store data exist, and creates them if they do not.
Upon tearing down the feast project, the registry ensures that the tables are dropped from the database.
The schema for how data is laid out in tables can be found . It is intentionally simple, storing the serialized protobuf versions of each Feast object keyed by its name.
The SQL Registry should be used when materializing feature views concurrently to ensure correctness of data in the registry. This can be achieved by simply running feast materialize or feature_store.materialize multiple times using a correctly configured feature_store.yaml. This will make each materialization process talk to the registry database concurrently, and ensure the metadata updates are serialized.
repo_config = RepoConfig(
registry=RegistryConfig(path="gs://feast-test-gcs-bucket/registry.pb"),
project="feast_demo_gcp",
provider="gcp",
offline_store="file", # Could also be the OfflineStoreConfig e.g. FileOfflineStoreConfig
online_store="null", # Could also be the OnlineStoreConfig e.g. RedisOnlineStoreConfig
)
store = FeatureStore(config=repo_config)
$ feast repo-upgrade --write
--- /Users/achal/feast/prompt_dory/example.py
+++ /Users/achal/feast/prompt_dory/example.py
@@ -13,7 +13,6 @@
path="/Users/achal/feast/prompt_dory/data/driver_stats.parquet",
event_timestamp_column="event_timestamp",
created_timestamp_column="created",
- date_partition_column="created"
)
# Define an entity for the driver. You can think of entity as a primary key used to
--- /Users/achal/feast/prompt_dory/example.py
+++ /Users/achal/feast/prompt_dory/example.py
@@ -3,7 +3,7 @@
from google.protobuf.duration_pb2 import Duration
import pandas as pd
-from feast import Entity, Feature, FeatureView, FileSource, ValueType, FeatureService, OnDemandFeatureView
+from feast import Entity, FeatureView, FileSource, ValueType, FeatureService, OnDemandFeatureView
# Read data from parquet files. Parquet is convenient for local development mode. For
# production, you can use your favorite DWH, such as BigQuery. See Feast documentation
--- /Users/achal/feast/prompt_dory/example.py
+++ /Users/achal/feast/prompt_dory/example.py
@@ -4,6 +4,7 @@
import pandas as pd
from feast import Entity, Feature, FeatureView, FileSource, ValueType, FeatureService, OnDemandFeatureView
+from feast import Field
# Read data from parquet files. Parquet is convenient for local development mode. For
# production, you can use your favorite DWH, such as BigQuery. See Feast documentation
--- /Users/achal/feast/prompt_dory/example.py
+++ /Users/achal/feast/prompt_dory/example.py
@@ -28,9 +29,9 @@
entities=[driver_id],
ttl=Duration(seconds=86400 * 365),
features=[
- Feature(name="conv_rate", dtype=ValueType.FLOAT),
- Feature(name="acc_rate", dtype=ValueType.FLOAT),
- Feature(name="avg_daily_trips", dtype=ValueType.INT64),
+ Field(name="conv_rate", dtype=ValueType.FLOAT),
+ Field(name="acc_rate", dtype=ValueType.FLOAT),
+ Field(name="avg_daily_trips", dtype=ValueType.INT64),
],
online=True,
batch_source=driver_hourly_stats,
$ feast repo-upgrade --write
from datetime import timedelta
from feast import Field, FileSource, KafkaSource, stream_feature_view
from feast.data_format import JsonFormat
from feast.types import Float32
driver_stats_batch_source = FileSource(
name="driver_stats_source",
path="data/driver_stats.parquet",
timestamp_field="event_timestamp",
)
driver_stats_stream_source = KafkaSource(
name="driver_stats_stream",
kafka_bootstrap_servers="localhost:9092",
topic="drivers",
timestamp_field="event_timestamp",
batch_source=driver_stats_batch_source,
message_format=JsonFormat(
schema_json="driver_id integer, event_timestamp timestamp, conv_rate double, acc_rate double, created timestamp"
),
watermark_delay_threshold=timedelta(minutes=5),
)
project: my_feature_app
registry: data/registry.db
provider: local
online_store:
## Basic Configs ##
# If apikey or host is left blank the driver will try to pull
# these values from environment variables ROCKSET_APIKEY and
# ROCKSET_APISERVER respectively.
type: rockset
api_key: <your_api_key_here>
host: <your_region_endpoint_here>
## Advanced Configs ##
# Batch size of records that will be turned per page when
# paginating a batched read.
#
# read_pagination_batch_size: 100
# The amount of time, in seconds, we will wait for the
# collection to become visible to the API.
#
# collection_created_timeout_secs: 60
# The amount of time, in seconds, we will wait for the
# collection to enter READY state.
#
# collection_ready_timeout_secs: 1800
# Whether to wait for all writes to be flushed from log
# and queryable before returning write as completed. If
# False, documents that are written may not be seen
# immediately in subsequent reads.
#
# fence_all_writes: True
# The amount of time we will wait, in seconds, for the
# write fence to be passed
#
# fence_timeout_secs: 600
# Initial backoff, in seconds, we will wait between
# requests when polling for a response.
#
# initial_request_backoff_secs: 2
# Initial backoff, in seconds, we will wait between
# requests when polling for a response.
# max_request_backoff_secs: 30
# The max amount of times we will retry a failed request.
# max_request_attempts: 10000
feast init -t snowflake {feature_repo_name}
Snowflake Deployment URL (exclude .snowflakecomputing.com):
Snowflake User Name::
Snowflake Password::
Snowflake Role Name (Case Sensitive)::
Snowflake Warehouse Name (Case Sensitive)::
Snowflake Database Name (Case Sensitive)::
Should I upload example data to Snowflake (overwrite table)? [Y/n]: Y
cd {feature_repo_name}
tabular data as data sources. There are many kinds of possible data sources:
Batch data sources: ideally, these live in data warehouses (BigQuery, Snowflake, Redshift), but can be in data lakes (S3, GCS, etc). Feast supports ingesting and querying data across both.
Stream data sources: Feast does not have native streaming integrations. It does however facilitate making streaming features available in different environments. There are two kinds of sources:
Push sources allow users to push features into Feast, and make it available for training / batch scoring ("offline"), for realtime feature serving ("online") or both.
[Alpha] Stream sources allow users to register metadata from Kafka or Kinesis sources. The onus is on the user to ingest from these sources, though Feast provides some limited helper methods to ingest directly from Kafka / Kinesis topics.
(Experimental) Request data sources: This is data that is only available at request time (e.g. from a user action that needs an immediate model prediction response). This is primarily relevant as an input into , which allow light-weight feature engineering and combining features across sources.
Ingesting from batch sources is only necessary to power real-time models. This is done through materialization. Under the hood, Feast manages an offline store (to scalably generate training data from batch sources) and an online store (to provide low-latency access to features for real-time models).
A key command to use in Feast is the materialize_incremental command, which fetches the latest values for all entities in the batch source and ingests these values into the online store.
Materialization can be called programmatically or through the CLI:
If the schema parameter is not specified when defining a data source, Feast attempts to infer the schema of the data source during feast apply. The way it does this depends on the implementation of the offline store. For the offline stores that ship with Feast out of the box this inference is performed by inspecting the schema of the table in the cloud data warehouse, or if a query is provided to the source, by running the query with a LIMIT clause and inspecting the result.
Ingesting from stream sources happens either via a Push API or via a contrib processor that leverages an existing Spark context.
To push data into the offline or online stores: see push sources for details.
This snippet creates a feature store object which points to the registry (which knows of all defined features) and the online store (DynamoDB in this case), and
Code example: CLI based materialization
How to run this in the CLI
How to run this on Airflow
Batch data schema inference
Stream data ingestion
.
If you're using a file based registry, then you'll also need to install the relevant cloud extra (pip install 'feast[snowflake, CLOUD]' where CLOUD is one of aws, gcp, azure)
You can get started by then running feast init -t snowflake.
The set of functionality supported by offline stores is described in detail here. Below is a matrix indicating which functionality is supported by the Snowflake offline store.
The set of functionality supported by offline stores is described in detail here. Below is a matrix indicating which functionality is supported by the BigQuery offline store.
pull_all_from_table_or_query (retrieve a saved dataset)
Below is a matrix indicating which functionality is supported by BigQueryRetrievalJob.
BigQuery
export to dataframe
yes
export to arrow table
yes
export to arrow batches
*See GitHub issue for details on proposed solutions for enabling the BigQuery offline store to understand tables that use _PARTITIONTIME as the partition column.
To compare this set of functionality against other offline stores, please see the full functionality matrix.
The set of functionality supported by offline stores is described in detail here. Below is a matrix indicating which functionality is supported by the Spark offline store.
Note that sslmode, sslkey_path, sslcert_path, and sslrootcert_path are optional parameters. The full set of configuration options is available in PostgreSQLOfflineStoreConfig.
The set of functionality supported by offline stores is described in detail here. Below is a matrix indicating which functionality is supported by the PostgreSQL offline store.
The set of functionality supported by offline stores is described in detail here. Below is a matrix indicating which functionality is supported by the Spark offline store.
The set of functionality supported by online stores is described in detail here. Below is a matrix indicating which functionality is supported by the Postgres online store.
Postgres
write feature values to the online store
yes
read feature values from the online store
yes
update infrastructure (e.g. tables) in the online store
To compare this set of functionality against other online stores, please see the full functionality matrix.
This implementation inherits all strengths of Hazelcast such as high availability, fault-tolerance, and data distribution.
Secure TSL/SSL connection is supported by Hazelcast online store.
You can set TTL (Time-To-Live) setting for your features in Hazelcast cluster.
Each feature view corresponds to an IMap in Hazelcast cluster and the entries in that IMap corresponds to features of entities. Each feature value stored separately and can be retrieved individually.
In order to use Hazelcast online store, you'll need to run pip install 'feast[hazelcast]'. You can then get started with the command feast init REPO_NAME -t hazelcast.
```yaml project: my_feature_repo registry: data/registry.db provider: local online_store: type: hazelcast cluster_name: dev cluster_members: ["localhost:5701"] key_ttl_seconds: 36000 ```
Hazelcast
write feature values to the online store
yes
read feature values from the online store
yes
update infrastructure (e.g. tables) in the online store
To compare this set of functionality against other online stores, please see the full functionality matrix.
All Feast operations execute through a provider. Operations like materializing data from the offline to the online store, updating infrastructure like databases, launching streaming ingestion jobs, building training datasets, and reading features from the online store.
Custom providers allow Feast users to extend Feast to execute any custom logic. Examples include:
Launching custom streaming ingestion jobs (Spark, Beam)
Launching custom batch ingestion (materialization) jobs (Spark, Beam)
Adding custom validation to feature repositories during feast apply
Adding custom infrastructure setup logic which runs during feast apply
Extending Feast commands with in-house metrics, logging, or tracing
Feast comes with built-in providers, e.g, LocalProvider, GcpProvider, and AwsProvider. However, users can develop their own providers by creating a class that implements the contract in the .
The fastest way to add custom logic to Feast is to extend an existing provider. The most generic provider is the LocalProvider which contains no cloud-specific logic. The guide that follows will extend the LocalProvider with operations that print text to the console. It is up to you as a developer to add your custom code to the provider methods, but the guide below will provide the necessary scaffolding to get you started.
The first step is to define a custom provider class. We've created the MyCustomProvider below.
Notice how in the above provider we have only overwritten two of the methods on the LocalProvider, namely update_infra and materialize_single_feature_view. These two methods are convenient to replace if you are planning to launch custom batch or streaming jobs. update_infra can be used for launching idempotent streaming jobs, and materialize_single_feature_view can be used for launching batch ingestion jobs.
It is possible to overwrite all the methods on the provider class. In fact, it isn't even necessary to subclass an existing provider like LocalProvider. The only requirement for the provider class is that it follows the .
Configure your file to point to your new provider class:
Notice how the provider field above points to the module and class where your provider can be found.
Now you should be able to use your provider by running a Feast command:
It may also be necessary to add the module root path to your PYTHONPATH as follows:
That's it. You should now have a fully functional custom provider!
Have a look at the for a fully functional example of a custom provider. Feel free to fork it when creating your own custom provider!
Snowflake
Description
The Snowflake online store provides support for materializing feature values into a Snowflake Transient Table for serving online features.
Only the latest feature values are persisted
The data model for using a Snowflake Transient Table as an online store follows a tall format (one row per feature)):
"entity_feature_key" (BINARY) -- unique key used when reading specific feature_view x entity combination
"entity_key" (BINARY) -- repeated key currently unused for reading entity_combination
"feature_name" (VARCHAR)
"value" (BINARY)
"event_ts" (TIMESTAMP)
"created_ts" (TIMESTAMP)
(This model may be subject to change when Snowflake Hybrid Tables are released)
In order to use this online store, you'll need to run pip install 'feast[snowflake]'. You can then get started with the command feast init REPO_NAME -t snowflake.
"snowflake-online-store/online_path": Adding the "snowflake-online-store/online_path" key to a FeatureView tags parameter allows you to choose the online table path for the online serving table (ex. "{database}"."{schema}").
The full set of configuration options is available in .
The set of functionality supported by online stores is described in detail . Below is a matrix indicating which functionality is supported by the Snowflake online store.
Snowflake
To compare this set of functionality against other online stores, please see the full .
Redis
Description
The Redis online store provides support for materializing feature values into Redis.
Both Redis and Redis Cluster are supported.
The data model used to store feature values in Redis is described in more detail here.
Getting started
In order to use this online store, you'll need to install the redis extra (along with the dependency needed for the offline store of choice). E.g.
pip install 'feast[gcp, redis]'
pip install 'feast[snowflake, redis]'
pip install 'feast[aws, redis]'
You can get started by using any of the other templates (e.g. feast init -t gcp or feast init -t snowflake or feast init -t aws), and then swapping in Redis as the online store as seen below in the examples.
Connecting to a single Redis instance:
Connecting to a Redis Cluster with SSL enabled and password authentication:
Additionally, the redis online store also supports automatically deleting data via a TTL mechanism. The TTL is applied at the entity level, so feature values from any associated feature views for an entity are removed together. This TTL can be set in the feature_store.yaml, using the key_ttl_seconds field in the online store. For example:
The full set of configuration options is available in .
The set of functionality supported by online stores is described in detail . Below is a matrix indicating which functionality is supported by the Redis online store.
Redis
To compare this set of functionality against other online stores, please see the full .
Dragonfly
Description
Dragonfly is a modern in-memory datastore that implements novel algorithms and data structures on top of a multi-threaded, share-nothing architecture. Thanks to its API compatibility, Dragonfly can act as a drop-in replacement for Redis. Due to Dragonfly's hardware efficiency, you can run a single node instance on a small 8GB instance or scale vertically to large 768GB machines with 64 cores. This greatly reduces infrastructure costs as well as architectural complexity.
Similar to Redis, Dragonfly can be used as an online feature store for Feast.
Using Dragonfly as a drop-in Feast online store instead of Redis
Make sure you have Python and pip installed.
Install the Feast SDK and CLI
pip install feast
In order to use Dragonfly as the online store, you'll need to install the redis extra:
pip install 'feast[redis]'
Bootstrap a new feature repository:
Update feature_repo/feature_store.yaml with the below contents:
There are several options available to get Dragonfly up and running quickly. We will be using Docker for this tutorial.
docker run --network=host --ulimit memlock=-1 docker.dragonflydb.io/dragonflydb/dragonfly
feast apply
The apply command scans python files in the current directory (example_repo.py in this case) for feature view/entity definitions, registers the objects, and deploys infrastructure. You should see the following output:
The set of functionality supported by online stores is described in detail . Below is a matrix indicating which functionality is supported by the Redis online store.
Redis
To compare this set of functionality against other online stores, please see the full .
Overview
In Feast, each batch data source is associated with a corresponding offline store. For example, a SnowflakeSource can only be processed by the Snowflake offline store. Otherwise, the primary difference between batch data sources is the set of supported types. Feast has an internal type system, and aims to support eight primitive types (bytes, string, int32, int64, float32, float64, bool, and timestamp) along with the corresponding array types. However, not every batch data source supports all of these types.
Google Cloud Platform
Offline Store: Uses the BigQuery offline store by default. Also supports File as the offline store.
Online Store: Uses the Datastore online store by default. Also supports Sqlite as an online store.
In order to use this offline store, you'll need to run pip install 'feast[gcp]'. You can get started by then running feast init -t gcp
Azure Synapse + Azure SQL (contrib)
MsSQL data sources are Microsoft sql table sources. These can be specified either by a table reference or a SQL query.
The MsSQL data source does not achieve full test coverage. Please do not assume complete stability.
Defining a MsSQL source:
yes
offline_write_batch (persist dataframes to offline store)
yes
write_logged_features (persist logged features to offline store)
yes
yes
export to SQL
yes
export to data lake (S3, GCS, etc.)
yes
export to data warehouse
yes
export as Spark dataframe
yes
local execution of Python-based on-demand transforms
yes
remote execution of Python-based on-demand transforms
no
persist results in the offline store
yes
preview the query plan before execution
yes
read partitioned data
yes
yes
offline_write_batch (persist dataframes to offline store)
yes
write_logged_features (persist logged features to offline store)
yes
no
export to SQL
yes
export to data lake (S3, GCS, etc.)
no
export to data warehouse
yes
export as Spark dataframe
no
local execution of Python-based on-demand transforms
yes
remote execution of Python-based on-demand transforms
no
persist results in the offline store
yes
preview the query plan before execution
yes
read partitioned data*
partial
yes
offline_write_batch (persist dataframes to offline store)
no
write_logged_features (persist logged features to offline store)
no
no
export to SQL
no
export to data lake (S3, GCS, etc.)
no
export to data warehouse
no
export as Spark dataframe
yes
local execution of Python-based on-demand transforms
no
remote execution of Python-based on-demand transforms
no
persist results in the offline store
yes
preview the query plan before execution
yes
read partitioned data
yes
yes
offline_write_batch (persist dataframes to offline store)
no
write_logged_features (persist logged features to offline store)
no
no
export to SQL
yes
export to data lake (S3, GCS, etc.)
yes
export to data warehouse
yes
export as Spark dataframe
no
local execution of Python-based on-demand transforms
yes
remote execution of Python-based on-demand transforms
no
persist results in the offline store
yes
preview the query plan before execution
yes
read partitioned data
yes
yes
offline_write_batch (persist dataframes to offline store)
no
write_logged_features (persist logged features to offline store)
no
no
export to SQL
no
export to data lake (S3, GCS, etc.)
no
export to data warehouse
no
local execution of Python-based on-demand transforms
no
remote execution of Python-based on-demand transforms
no
persist results in the offline store
yes
yes
teardown infrastructure (e.g. tables) in the online store
yes
generate a plan of infrastructure changes
no
support for on-demand transforms
yes
readable by Python SDK
yes
readable by Java
no
readable by Go
no
support for entityless feature views
yes
support for concurrent writing to the same key
no
support for ttl (time to live) at retrieval
no
support for deleting expired data
no
collocated by feature view
yes
collocated by feature service
no
collocated by entity key
no
yes
teardown infrastructure (e.g. tables) in the online store
yes
generate a plan of infrastructure changes
no
support for on-demand transforms
yes
readable by Python SDK
yes
readable by Java
no
readable by Go
no
support for entityless feature views
yes
support for concurrent writing to the same key
yes
support for ttl (time to live) at retrieval
yes
support for deleting expired data
yes
collocated by feature view
no
collocated by feature service
no
collocated by entity key
yes
This guide also comes with a fully functional custom provider demo repository. Please have a look at the repository for a representative example of what a custom provider looks like, or fork the repository when creating your own provider.
....
Created entity driver
Created feature view driver_hourly_stats_fresh
Created feature view driver_hourly_stats
Created on demand feature view transformed_conv_rate
Created on demand feature view transformed_conv_rate_fresh
Created feature service driver_activity_v1
Created feature service driver_activity_v3
Created feature service driver_activity_v2
For more details on the Feast type system, see here.
There are currently four core batch data source implementations: FileSource, BigQuerySource, SnowflakeSource, and RedshiftSource. There are several additional implementations contributed by the Feast community (PostgreSQLSource, SparkSource, and TrinoSource), which are not guaranteed to be stable or to match the functionality of the core implementations. Details for each specific data source can be found here.
Below is a matrix indicating which data sources support which types.
The list below contains the functionality that contributors are planning to develop for Feast.
We welcome contribution to all items in the roadmap!
Data Sources
Offline Stores
Online Stores
Feature Engineering
Streaming
Deployments
Feature Serving
Data Quality Management (See )
Feature Discovery and Governance
Trino (contrib)
Description
The Trino offline store provides support for reading TrinoSources.
Entity dataframes can be provided as a SQL query or can be provided as a Pandas dataframe. A Pandas dataframes will be uploaded to Trino as a table in order to complete join operations.
Disclaimer
The Trino offline store does not achieve full test coverage. Please do not assume complete stability.
Getting started
In order to use this offline store, you'll need to run pip install 'feast[trino]'. You can then run feast init, then swap out feature_store.yaml with the below example to connect to Trino.
The full set of configuration options is available in .
The set of functionality supported by offline stores is described in detail . Below is a matrix indicating which functionality is supported by the Trino offline store.
Trino
Below is a matrix indicating which functionality is supported by TrinoRetrievalJob.
Trino
To compare this set of functionality against other offline stores, please see the full .
Cassandra + Astra DB (contrib)
Description
The [Cassandra / Astra DB] online store provides support for materializing feature values into an Apache Cassandra / Astra DB database for online features.
The whole project is contained within a Cassandra keyspace
Each feature view is mapped one-to-one to a specific Cassandra table
This implementation inherits all strengths of Cassandra such as high availability, fault-tolerance, and data distribution
In order to use this online store, you'll need to run pip install 'feast[cassandra]'. You can then get started with the command feast init REPO_NAME -t cassandra.
The full set of configuration options is available in . For a full explanation of configuration options please look at file sdk/python/feast/infra/online_stores/contrib/cassandra_online_store/README.md.
Storage specifications can be found at docs/specs/online_store_format.md.
The set of functionality supported by online stores is described in detail . Below is a matrix indicating which functionality is supported by the Cassandra online store.
Cassandra
To compare this set of functionality against other online stores, please see the full .
Codebase Structure
Let's examine the Feast codebase. This analysis is accurate as of Feast 0.23.
$ tree -L 1 -d
.
├── docs
├── examples
├── go
├── infra
├── java
├── protos
├── sdk
└── ui
Python SDK
The Python SDK lives in sdk/python/feast. The majority of Feast logic lives in these Python files:
The core Feast objects (entities, feature views, data sources, etc.) are defined in their respective Python files, such as entity.py, feature_view.py, and data_source.py.
The FeatureStore class is defined in feature_store.py and the associated configuration object (the Python representation of the feature_store.yaml file) are defined in repo_config.py.
The CLI and other core feature store logic are defined in cli.py and repo_operations.py.
The type system that is used to manage conversion between Feast types and external typing systems is managed in type_map.py.
The Python feature server (the server that is started through the feast serve command) is defined in feature_server.py.
There are also several important submodules:
infra/ contains all the infrastructure components, such as the provider, offline store, online store, batch materialization engine, and registry.
dqm/ covers data quality monitoring, such as the dataset profiler.
diff/
Of these submodules, infra/ is the most important. It contains the interfaces for the , , , , and , as well as all of their individual implementations.
The tests for the Python SDK are contained in sdk/python/tests. For more details, see this of the test suite.
Let's walk through how feast apply works by tracking its execution across the codebase.
All CLI commands are in cli.py. Most of these commands are backed by methods in repo_operations.py. The feast apply command triggers apply_total_command, which then calls apply_total in repo_operations.py.
At this point, the feast apply command is complete.
Let's walk through how feast materialize works by tracking its execution across the codebase.
The feast materialize command triggers materialize_command in cli.py, which then calls FeatureStore.materialize from feature_store.py.
This then calls Provider.materialize_single_feature_view
Let's walk through how get_historical_features works by tracking its execution across the codebase.
We start with FeatureStore.get_historical_features in feature_store.py. This method does some internal preparation, and then delegates the actual execution to the underlying provider by calling Provider.get_historical_features, which can be found in infra/provider.py.
As with feast apply, the provider is most likely backed by the passthrough provider, in which case PassthroughProvider.get_historical_features
The java/ directory contains the Java serving component. See for more details on how the repo is structured.
The go/ directory contains the Go feature server. Most of the files here have logic to help with reading features from the online store. Within go/, the internal/feast/ directory contains most of the core logic:
onlineserving/ covers the core serving logic.
model/ contains the implementations of the Feast objects (entity, feature view, etc.).
For example,
Feast uses to store serialized versions of the core Feast objects. The protobuf definitions are stored in protos/feast.
The consists of the serialized representations of the Feast objects.
Typically, changes being made to the Feast objects require changes to their corresponding protobuf representations. The usual best practices for making changes to protobufs should be followed ensure backwards and forwards compatibility.
The ui/ directory contains the Web UI. See for more details on the structure of the Web UI.
Bytewax
Description
The Bytewax batch materialization engine provides an execution engine for batch materializing operations (materialize and materialize-incremental).
Guide
In order to use the Bytewax materialization engine, you will need a Kubernetes cluster running version 1.22.10 or greater.
Kubernetes Authentication
The Bytewax materialization engine loads authentication and cluster information from the kubeconfig file. By default, kubectl looks for a file named config in the $HOME/.kube directory. You can specify other kubeconfig files by setting the KUBECONFIG environment variable.
Resource Authentication
Bytewax jobs can be configured to access as environment variables to access online and offline stores during job runs.
To configure secrets, first create them using kubectl:
If your Docker registry requires authentication to store/pull containers, you can use this same approach to store your repository access credential and use when running the materialization engine.
Then configure them in the batch_engine section of feature_store.yaml:
The Bytewax materialization engine is configured through the The feature_store.yaml configuration file:
Notes:
The namespace configuration directive specifies which Kubernetes jobs, services and configuration maps will be created in.
The image_pull_secrets configuration directive specifies the pre-configured secret to use when pulling the image container from your registry.
The image configuration directive specifies which container image to use when running the materialization job. To create a custom image based on this container, run the following command:
Once that image is built and pushed to a registry, it can be specified as a part of the batch engine configuration:
Provider
A provider is an implementation of a feature store using specific feature store components (e.g. offline store, online store) targeting a specific environment (e.g. GCP stack).
Providers orchestrate various components (offline store, online store, infrastructure, compute) inside an environment. For example, the gcp provider supports BigQuery as an offline store and Datastore as an online store, ensuring that these components can work together seamlessly. Feast has three built-in providers (local, gcp, and aws) with default configurations that make it easy for users to start a feature store in a specific environment. These default configurations can be overridden easily. For instance, you can use the gcp provider but use Redis as the online store instead of Datastore.
If the built-in providers are not sufficient, you can create your own custom provider. Please see for more details.
covers the logic for determining how to apply infrastructure changes upon feature repo changes (e.g. the output of
feast plan
and
feast apply
).
embedded_go/ covers the Go feature server.
ui/ contains the embedded Web UI, to be launched on the feast ui command.
With a
FeatureStore
object (from
feature_store.py
) that is initialized based on the
feature_store.yaml
in the current working directory,
apply_total
first parses the feature repo with
parse_repo
and then calls either
FeatureStore.apply
or
FeatureStore._apply_diffs
to apply those changes to the feature store.
Let's examine FeatureStore.apply. It splits the objects based on class (e.g. Entity, FeatureView, etc.) and then calls the appropriate registry method to apply or delete the object. For example, it might call self._registry.apply_entity to apply an entity. If the default file-based registry is used, this logic can be found in infra/registry/registry.py.
Then the feature store must update its cloud infrastructure (e.g. online store tables) to match the new feature repo, so it calls Provider.update_infra, which can be found in infra/provider.py.
Assuming the provider is a built-in provider (e.g. one of the local, GCP, or AWS providers), it will call PassthroughProvider.update_infra in infra/passthrough_provider.py.
This delegates to the online store and batch materialization engine. For example, if the feature store is configured to use the Redis online store then the update method from infra/online_stores/redis.py will be called. And if the local materialization engine is configured then the update method from infra/materialization/local_engine.py will be called.
, which can be found in
infra/provider.py
.
As with feast apply, the provider is most likely backed by the passthrough provider, in which case PassthroughProvider.materialize_single_feature_view will be called.
This delegates to the underlying batch materialization engine. Assuming that the local engine has been configured, LocalMaterializationEngine.materialize from infra/materialization/local_engine.py will be called.
Since materialization involves reading features from the offline store and writing them to the online store, the local engine will delegate to both the offline store and online store. Specifically, it will call OfflineStore.pull_latest_from_table_or_query and OnlineStore.online_write_batch. These two calls will be routed to the offline store and online store that have been configured.
will be called.
That call simply delegates to OfflineStore.get_historical_features. So if the feature store is configured to use Snowflake as the offline store, SnowflakeOfflineStore.get_historical_features will be executed.
entity.go
is the Go equivalent of
entity.py
. It contains a very simple Go implementation of the entity object.
registry/ covers the registry.
Currently only the file-based registry supported (the sql-based registry is unsupported). Additionally, the file-based registry only supports a file-based registry store, not the GCS or S3 registry stores.
onlinestore/ covers the online stores (currently only Redis and SQLite are supported).
The service_account_name specifies which Kubernetes service account to run the job under.
The include_security_context_capabilities flag indicates whether or not "add": ["NET_BIND_SERVICE"] and "drop": ["ALL"] are included in the job & pod security context capabilities.
annotations allows you to include additional Kubernetes annotations to the job. This is particularly useful for IAM roles which grant the running pod access to cloud platform resources (for example).
The resources configuration directive sets the standard Kubernetes resource requests for the job containers to utilise when materializing data.
How does Feast handle model or feature versioning?
Feast expects that each version of a model corresponds to a different feature service.
Feature views once they are used by a feature service are intended to be immutable and not deleted (until a feature service is removed). In the future, feast plan and feast apply will throw errors if it sees this kind of behavior.
What is the difference between data sources and the offline store?
The data source itself defines the underlying data warehouse table in which the features are stored. The offline store interface defines the APIs required to make an arbitrary compute layer work for Feast (e.g. pulling features given a set of feature views from their sources, exporting the data set results to different formats). Please see and for more details.
Yes, this is possible. For example, you can use BigQuery as an offline store and Redis as an online store.
Feast does not provide a way to do this right now. This is an area we're actively interested in contributions for. See
Feast currently does not support any access control other than the access control required for the Provider's environment (for example, GCP and AWS permissions).
It is a good idea though to lock down the registry file so only the CI/CD pipeline can modify it. That way data scientists and other users cannot accidentally modify the registry and lose other team's data.
Yes. In earlier versions of Feast, we used Feast Spark to manage ingestion from stream sources. In the current version of Feast, we support . Feast also defines a that allows a deeper integration with stream sources.
There are several kinds of transformations:
On demand transformations (See )
These transformations are Pandas transformations run on batch data when you call get_historical_features and at online serving time when you call `get_online_features.
Note that if you use push sources to ingest streaming features, these transformations will execute on the fly as well
Yes. See .
A feature view can be defined with multiple entities. Since each entity has a unique join_key, using multiple entities will achieve the effect of a composite key.
Please see a detailed comparison of Feast vs. Tecton . For another comparison, please see .
Feast is designed to work at scale and support low latency online serving. See our for details.
Yes. Specifically:
Simple lists / dense embeddings:
BigQuery supports list types natively
Redshift does not support list types, so you'll need to serialize these features into strings (e.g. json or protocol buffers)
The list of supported offline and online stores can be found and , respectively. The indicates the stores for which we are planning to add support. Finally, our Provider abstraction is built to be extensible, so you can plug in your own implementations of offline and online stores. Please see more details about customizing Feast .
Yes. Using a GCP or AWS provider in feature_store.yaml primarily sets default offline / online stores and configures where the remote registry file can live (Using the AWS provider also allows for deployment to AWS Lambda). You can override the offline and online stores to be in different clouds if you wish.
The data source and the offline store are closely tied, but separate concepts. The offline store controls how feast talks to a data store for historical feature retrieval, and the data source points to specific table (or query) within a data store. Offline stores are infrastructure-level connectors to data stores like Snowflake.
Additional differences:
Data sources may be specific to a project (e.g. feed ranking), but offline stores are agnostic and used across projects.
A feast project may define several data sources that power different feature views, but a feast project has a single offline store.
Feast users typically need to define data sources when using feast, but only need to use/configure existing offline stores without creating new ones.
Please follow the instructions .
Yes. For example, the Postgres connector can be used as both an offline and online store (as well as the registry).
Yes. There are two ways to use S3 in Feast:
Using Redshift as a data source via Spectrum (), and then continuing with the guide. See a we did on this at our apply() meetup.
Using the s3_endpoint_override in a FileSource data source. This endpoint is more suitable for quick proof of concepts that won't necessarily scale for production use cases.
Please see the .
For more details on contributing to the Feast community, see and this .
Feast 0.10+ is much lighter weight and more extensible than Feast 0.9. It is designed to be simple to install and use. Please see this for more details.
Please see this . If you have any questions or suggestions, feel free to leave a comment on the document!
Feast Core and Feast Serving were both part of Feast Java. We plan to support Feast Serving. We will not support Feast Core; instead we will support our object store based registry. We will not support Feast Spark. For more details on what we plan on supporting, please see the .
Driver ranking
Making a prediction using a linear regression model is a common use case in ML. This model predicts if a driver will complete a trip based on features ingested into Feast.
In this example, you'll learn how to use some of the key functionality in Feast. The tutorial runs in both local mode and on the Google Cloud Platform (GCP). For GCP, you must have access to a GCP project already, including read and write permissions to BigQuery.
This tutorial guides you on how to use Feast with . You will learn how to:
Train a model locally (on your laptop) using data from
A feature view is an object that represents a logical group of time-series feature data as it is found in a . Depending on the kind of feature view, it may contain some lightweight (experimental) feature transformations (see ).
Feature views consist of:
a
zero or more
Overview
Here are the methods exposed by the OfflineStore interface, along with the core functionality supported by the method:
get_historical_features: point-in-time correct join to retrieve historical features
pull_latest_from_table_or_query
If the features are not related to a specific object, the feature view might not have entities; see feature views without entities below.
a name to uniquely identify this feature view in the project.
(optional, but recommended) a schema specifying one or more features (without this, Feast will infer the schema by reading from the data source)
(optional, but recommended) metadata (for example, description, or other free-form metadata via tags)
(optional) a TTL, which limits how far back Feast will look when generating historical datasets
Feature views allow Feast to model your existing feature data in a consistent way in both an offline (training) and online (serving) environment. Feature views generally contain features that are properties of a specific object, in which case that object is defined as an entity and included in the feature view.
from feast import BigQuerySource, Entity, FeatureView, Field
Feature views are used during
The generation of training datasets by querying the data source of feature views in order to find historical feature values. A single training dataset may consist of features from multiple feature views.
Loading of feature values into an online store. Feature views determine the storage schema in the online store. Feature values can be loaded from batch sources or from stream sources.
Retrieval of features from the online store. Feature views provide the schema definition to Feast in order to look up features from the online store.
If a feature view contains features that are not related to a specific entity, the feature view can be defined without entities (only timestamps are needed for this feature view).
from feast import BigQuerySource, FeatureView, Field
from feast.types import Int64
global_stats_fv = FeatureView(
name="global_stats",
entities=[],
schema=[
Field(name="total_trips_today_by_all_drivers", dtype=Int64),
],
source=BigQuerySource(
table="feast-oss.demo_data.global_stats"
)
)
If the schema parameter is not specified in the creation of the feature view, Feast will infer the features during feast apply by creating a Field for each column in the underlying data source except the columns corresponding to the entities of the feature view or the columns corresponding to the timestamp columns of the feature view's data source. The names and value types of the inferred features will use the names and data types of the columns from which the features were inferred.
"Entity aliases" can be specified to join entity_dataframe columns that do not match the column names in the source table of a FeatureView.
This could be used if a user has no control over these column names or if there are multiple entities are a subclass of a more general entity. For example, "spammer" and "reporter" could be aliases of a "user" entity, and "origin" and "destination" could be aliases of a "location" entity as shown below.
It is suggested that you dynamically specify the new FeatureView name using .with_name and join_key_map override using .with_join_key_map instead of needing to register each new copy.
from feast import BigQuerySource, Entity, FeatureView, Field
from feast.types import Int32, Int64
location = Entity(name="location", join_keys=["location_id"])
location_stats_fv= FeatureView(
name="location_stats",
entities=[location],
schema=[
Field(name="temperature", dtype=Int32),
Field(name="location_id", dtype=Int64),
],
source=BigQuerySource(
table="feast-oss.demo_data.location_stats"
),
)
A field or feature is an individual measurable property. It is typically a property observed on a specific entity, but does not have to be associated with an entity. For example, a feature of a customer entity could be the number of transactions they have made on an average month, while a feature that is not observed on a specific entity could be the total number of posts made by all users in the last month. Supported types for fields in Feast can be found in sdk/python/feast/types.py.
Fields are defined as part of feature views. Since Feast does not transform data, a field is essentially a schema that only contains a name and a type:
Together with data sources, they indicate to Feast where to find your feature values, e.g., in a specific parquet file or BigQuery table. Feature definitions are also used when reading features from the feature store, using feature references.
Feature names must be unique within a feature view.
Each field can have additional metadata associated with it, specified as key-value tags.
On demand feature views allows data scientists to use existing features and request time data (features only available at request time) to transform and create new features. Users define python transformation logic which is executed in both the historical retrieval and online retrieval paths.
Currently, these transformations are executed locally. This is fine for online serving, but does not scale well to offline retrieval.
This enables data scientists to easily impact the online feature retrieval path. For example, a data scientist could
Call get_historical_features to generate a training dataframe
Iterate in notebook on feature engineering in Pandas
Copy transformation logic into on demand feature views and commit to a dev branch of the feature repository
Verify with get_historical_features (on a small dataset) that the transformation gives expected output over historical data
Verify with get_online_features on dev branch that the transformation correctly outputs online features
Submit a pull request to the staging / prod branches which impact production traffic
A stream feature view is an extension of a normal feature view. The primary difference is that stream feature views have both stream and batch data sources, whereas a normal feature view only has a batch data source.
Stream feature views should be used instead of normal feature views when there are stream data sources (e.g. Kafka and Kinesis) available to provide fresh features in an online setting. Here is an example definition of a stream feature view with an attached transformation:
See here for a example of how to use stream feature views to register your own streaming data pipelines in Feast.
Feature views
Note: Feature views do not work with non-timestamped data. A workaround is to insert dummy timestamps.
from feast import Field
from feast.types import Float32
trips_today = Field(
name="trips_today",
dtype=Float32
)
from feast import Field, RequestSource
from feast.on_demand_feature_view import on_demand_feature_view
from feast.types import Float64
# Define a request data source which encodes features / information only
# available at request time (e.g. part of the user initiated HTTP request)
input_request = RequestSource(
name="vals_to_add",
schema=[
Field(name="val_to_add", dtype=PrimitiveFeastType.INT64),
Field(name="val_to_add_2": dtype=PrimitiveFeastType.INT64),
]
)
# Use the input data and feature view features to create new features
@on_demand_feature_view(
sources=[
driver_hourly_stats_view,
input_request
],
schema=[
Field(name='conv_rate_plus_val1', dtype=Float64),
Field(name='conv_rate_plus_val2', dtype=Float64)
]
)
def transformed_conv_rate(features_df: pd.DataFrame) -> pd.DataFrame:
df = pd.DataFrame()
df['conv_rate_plus_val1'] = (features_df['conv_rate'] + features_df['val_to_add'])
df['conv_rate_plus_val2'] = (features_df['conv_rate'] + features_df['val_to_add_2'])
return df
: retrieve latest feature values for materialization into the online store
pull_all_from_table_or_query: retrieve a saved dataset
offline_write_batch: persist dataframes to the offline store, primarily for push sources
write_logged_features: persist logged features to the offline store, for feature logging
The first three of these methods all return a RetrievalJob specific to an offline store, such as a SnowflakeRetrievalJob. Here is a list of functionality supported by RetrievalJobs:
export to dataframe
export to arrow table
export to arrow batches (to handle large datasets in memory)
export to SQL
export to data lake (S3, GCS, etc.)
export to data warehouse
export as Spark dataframe
local execution of Python-based on-demand transforms
remote execution of Python-based on-demand transforms
persist results in the offline store
preview the query plan before execution (RetrievalJobs are lazily executed)
read partitioned data
There are currently four core offline store implementations: FileOfflineStore, BigQueryOfflineStore, SnowflakeOfflineStore, and RedshiftOfflineStore. There are several additional implementations contributed by the Feast community (PostgreSQLOfflineStore, SparkOfflineStore, and TrinoOfflineStore), which are not guaranteed to be stable or to match the functionality of the core implementations. Details for each specific offline store, such as how to configure it in a feature_store.yaml, can be found here.
Below is a matrix indicating which offline stores support which methods.
File
BigQuery
Snowflake
Redshift
Postgres
Spark
Trino
get_historical_features
Below is a matrix indicating which RetrievalJobs support what functionality.
The Redshift offline store provides support for reading RedshiftSources.
All joins happen within Redshift.
Entity dataframes can be provided as a SQL query or can be provided as a Pandas dataframe. A Pandas dataframes will be uploaded to Redshift temporarily in order to complete join operations.
Getting started
In order to use this offline store, you'll need to run pip install 'feast[aws]'. You can get started by then running feast init -t aws.
The full set of configuration options is available in .
The set of functionality supported by offline stores is described in detail . Below is a matrix indicating which functionality is supported by the Redshift offline store.
Redshift
Below is a matrix indicating which functionality is supported by RedshiftRetrievalJob.
Redshift
To compare this set of functionality against other offline stores, please see the full .
Feast requires the following permissions in order to execute commands for Redshift offline store:
The following inline policy can be used to grant Feast the necessary permissions:
In addition to this, Redshift offline store requires an IAM role that will be used by Redshift itself to interact with S3. More concretely, Redshift has to use this IAM role to run and commands. Once created, this IAM role needs to be configured in feature_store.yaml file as offline_store: iam_role.
The following inline policy can be used to grant Redshift necessary permissions to access S3:
While the following trust relationship is necessary to make sure that Redshift, and only Redshift can assume this role:
In order to use , specify a workgroup instead of a cluster_id and user.
Please note that the IAM policies above will need the version, rather than the standard .
Overview
Functionality
Here are the methods exposed by the OnlineStore interface, along with the core functionality supported by the method:
online_write_batch: write feature values to the online store
online_read: read feature values from the online store
update: update infrastructure (e.g. tables) in the online store
teardown: teardown infrastructure (e.g. tables) in the online store
plan: generate a plan of infrastructure changes based on feature repo changes
There is also additional functionality not properly captured by these interface methods:
support for on-demand transforms
readable by Python SDK
readable by Java
Finally, there are multiple data models for storing the features in the online store. For example, features could be:
collocated by feature view
collocated by feature service
collocated by entity key
See this for a discussion around the tradeoffs of each of these data models.
There are currently five core online store implementations: SqliteOnlineStore, RedisOnlineStore, DynamoDBOnlineStore, SnowflakeOnlineStore, and DatastoreOnlineStore. There are several additional implementations contributed by the Feast community (PostgreSQLOnlineStore, HbaseOnlineStore, and CassandraOnlineStore), which are not guaranteed to be stable or to match the functionality of the core implementations. Details for each specific online store, such as how to configure it in a feature_store.yaml, can be found .
Below is a matrix indicating which online stores support what functionality.
Running Feast in production (e.g. on Kubernetes)
Overview
After learning about Feast concepts and playing with Feast locally, you're now ready to use Feast in production. This guide aims to help with the transition from a sandbox project to production-grade deployment in the cloud or on-premise (e.g. on Kubernetes).
A typical production architecture looks like:
Overview
Important note: Feast is highly customizable and modular.
Most Feast blocks are loosely connected and can be used independently. Hence, you are free to build your own production configuration.
For example, you might not have a stream source and, thus, no need to write features in real-time to an online store. Or you might not need to retrieve online features. Feast also often provides multiple options to achieve the same goal. We discuss tradeoffs below.
In this guide we will show you how to:
Deploy your feature store and keep your infrastructure in sync with your feature repository
Keep the data in your online store up to date (from batch and stream sources)
Use Feast for model training and serving
The first step to setting up a deployment of Feast is to create a Git repository that contains your feature definitions. The recommended way to version and track your feature definitions is by committing them to a repository and tracking changes through commits. If you recall, running feast apply commits feature definitions to a registry, which users can then read elsewhere.
Out of the box, Feast serializes all of its state into a file-based registry. When running Feast in production, we recommend using the more scalable SQL-based registry that is backed by a database. Details are available .
Note: A SQL-based registry primarily works with a Python feature server. The Java feature server does not understand this registry type yet.
We recommend typically setting up CI/CD to automatically run feast plan and feast apply when pull requests are opened / merged.
A common scenario when using Feast in production is to want to test changes to Feast object definitions. For this, we recommend setting up a staging environment for your offline and online stores, which mirrors production (with potentially a smaller data set).
Having this separate environment allows users to test changes by first applying them to staging, and then promoting the changes to production after verifying the changes on staging.
Different options are presented in the .
To keep your online store up to date, you need to run a job that loads feature data from your feature view sources into your online store. In Feast, this loading operation is called materialization.
Out of the box, Feast's materialization process uses an in-process materialization engine. This engine loads all the data being materialized into memory from the offline store, and writes it into the online store.
This approach may not scale to large amounts of data, which users of Feast may be dealing with in production. In this case, we recommend using one of the more , such as the , or the . Users may also need to to work on their existing infrastructure.
The Bytewax materialization engine can run materialization on an existing Kubernetes cluster. An example configuration of this in a feature_store.yaml is as follows:
See also for code snippets
It is up to you to orchestrate and schedule runs of materialization.
Feast keeps the history of materialization in its registry so that the choice could be as simple as a . Cron util should be sufficient when you have just a few materialization jobs (it's usually one materialization job per feature view) triggered infrequently.
However, the amount of work can quickly outgrow the resources of a single machine. That happens because the materialization job needs to repackage all rows before writing them to an online store. That leads to high utilization of CPU and memory. In this case, you might want to use a job orchestrator to run multiple jobs in parallel using several workers. Kubernetes Jobs or Airflow are good choices for more comprehensive job orchestration.
If you are using Airflow as a scheduler, Feast can be invoked through a after the has been installed into a virtual environment and your feature repo has been synced:
You can see more in an example at .
See more details at , which shows how to ingest streaming features or 3rd party feature data via a push API.
This supports pushing feature values into Feast to both online or offline stores.
Feast does not orchestrate batch transformation DAGs. For this, you can rely on tools like Airflow + dbt. See for an example and some tips.
For more details, see
After we've defined our features and data sources in the repository, we can generate training datasets. We highly recommend you use a FeatureService to version the features that go into a specific model version.
The first thing we need to do in our training code is to create a FeatureStore object with a path to the registry.
One way to ensure your production clients have access to the feature store is to provide a copy of the feature_store.yaml to those pipelines. This feature_store.yaml file will have a reference to the feature store registry, which allows clients to retrieve features from offline or online stores.
The most common way to productionize ML models is by storing and versioning models in a "model store", and then deploying these models into production. When using Feast, it is recommended that the feature service name and the model versions have some established convention.
For example, in MLflow:
Once you have successfully loaded data from batch / streaming sources into the online store, you can start consuming features for model inference.
This approach is the most convenient to keep your infrastructure as minimalistic as possible and avoid deploying extra services. The Feast Python SDK will connect directly to the online store (Redis, Datastore, etc), pull the feature data, and run transformations locally (if required). The obvious drawback is that your service must be written in Python to use the Feast Python SDK. A benefit of using a Python stack is that you can enjoy production-grade services with integrations with many existing data science tools.
To integrate online retrieval into your service use the following code:
To deploy a Feast feature server on Kubernetes, you can use the included (which also has detailed instructions and an example tutorial).
Basic steps
Install and
Add the Feast Helm repository and download the latest charts:
Run Helm Install
This will deploy a single service. The service must have read access to the registry file on cloud storage and to the online store (e.g. via ). It will keep a copy of the registry in their memory and periodically refresh it, so expect some delays in update propagation in exchange for better performance.
You might want to dynamically set parts of your configuration from your environment. For instance to deploy Feast to production and development with the same configuration, but a different server. Or to inject secrets without exposing them in your git repo. To do this, it is possible to use the ${ENV_VAR} syntax in your feature_store.yaml file. For instance:
It is possible to set a default value if the environment variable is not set, with ${ENV_VAR:"default"}. For instance:
In summary, the overall architecture in production may look like:
Feast SDK is being triggered by CI (eg, Github Actions). It applies the latest changes from the feature repo to the Feast database-backed registry
Data ingestion
Batch data: Airflow manages batch transformation jobs + materialization jobs to ingest batch data from DWH to the online store periodically. When working with large datasets to materialize, we recommend using a batch materialization engine
Feature retrieval
Generally, Feast supports several patterns of feature retrieval:
Training data generation (via feature_store.get_historical_features(...))
Offline feature retrieval for batch scoring (via feature_store.get_historical_features(...))
Then, you need to generate an entity dataframe. You have two options
Create an entity dataframe manually and pass it in
Use a SQL query to dynamically generate lists of entities (e.g. all entities within a time range) and timestamps to pass into Feast
Then, training data can be retrieved as follows:
training_retrieval_job = fs.get_historical_features(
entity_df=entity_df_or_sql_string,
features=fs.get_feature_service("driver_activity_v1"),
)
# Option 1: In memory model training
model = ml.fit(training_retrieval_job.to_df())
# Option 2: Unloading to blob storage. Further post-processing can occur before kicking off distributed training.
training_retrieval_job.to_remote_storage()
If your offline and online workloads are in Snowflake, the Snowflake materialization engine is likely the best option.
If your offline and online workloads are not using Snowflake, but using Kubernetes is an option, the Bytewax materialization engine is likely the best option.
If none of these engines suite your needs, you may continue using the in-process engine, or write a custom engine (e.g with Spark or Ray).
Stream data: The Feast Push API is used within existing Spark / Beam pipelines to push feature values to offline / online stores
Online features are served via the Python feature server over HTTP, or consumed using the Feast Python SDK.
Feast Python SDK is called locally to generate a training dataset
Additionally, please check the how-to guide for some specific recommendations on how to scale Feast.
from airflow.decorators import task
from feast import RepoConfig, FeatureStore
from feast.infra.online_stores.dynamodb import DynamoDBOnlineStoreConfig
from feast.repo_config import RegistryConfig
# Define Python callable
@task()
def materialize(data_interval_start=None, data_interval_end=None):
repo_config = RepoConfig(
registry=RegistryConfig(path="s3://[YOUR BUCKET]/registry.pb"),
project="feast_demo_aws",
provider="aws",
offline_store="file",
online_store=DynamoDBOnlineStoreConfig(region="us-west-2"),
entity_key_serialization_version=2
)
store = FeatureStore(config=repo_config)
# Option 1: materialize just one feature view
# store.materialize_incremental(datetime.datetime.now(), feature_views=["my_fv_name"])
# Option 2: materialize all feature views incrementally
# store.materialize_incremental(datetime.datetime.now())
# Option 3: Let Airflow manage materialization state
# Add 1 hr overlap to account for late data
store.materialize(data_interval_start.subtract(hours=1), data_interval_end)
from feast import FeatureStore
fs = FeatureStore(repo_path="production/")
import mlflow.pyfunc
# Load model from MLflow
model_name = "my-model"
model_version = 1
model = mlflow.pyfunc.load_model(
model_uri=f"models:/{model_name}/{model_version}"
)
fs = FeatureStore(repo_path="production/")
# Read online features using the same model name and model version
feature_vector = fs.get_online_features(
features=fs.get_feature_service(f"{model_name}_v{model_version}"),
entity_rows=[{"driver_id": 1001}]
).to_dict()
# Make a prediction
prediction = model.predict(feature_vector)
from feast import FeatureStore
with open('feature_refs.json', 'r') as f:
feature_refs = json.loads(f)
fs = FeatureStore(repo_path="production/")
# Read online features
feature_vector = fs.get_online_features(
features=feature_refs,
entity_rows=[{"driver_id": 1001}]
).to_dict()
1. Automatically deploying changes to your feature definitions
1.1 Setting up a feature repository
1.2 Setting up a database-backed registry
1.3 Setting up CI/CD to automatically update the registry
1.4 Setting up multiple environments
2. How to load data into your online store and keep it up to date
2.1 Scalable Materialization
2.2 Scheduled materialization with Airflow
Important note: Airflow worker must have read and write permissions to the registry file on GCS / S3 since it pulls configuration and updates materialization history.
2.3 Stream feature ingestion
2.4 Scheduled batch transformations with Airflow + dbt
3. How to use Feast for model training
3.1. Generating training data
3.2 Versioning features that power ML models
It is important to note that both the training pipeline and model serving service need only read access to the feature registry and associated infrastructure. This prevents clients from accidentally making changes to the feature store.
4. Retrieving online features for prediction
4.1. Use the Python SDK within an existing Python service
4.2. Deploy Feast feature servers on Kubernetes
5. Using environment variables in your yaml configuration
From Repository to Production: Feast Production Architecture
Online feature retrieval for real-time model predictions
via the SDK: feature_store.get_online_features(...)
via deployed feature server endpoints: requests.post('http://localhost:6566/get-online-features', data=json.dumps(online_request))
Each of these retrieval mechanisms accept:
some way of specifying entities (to fetch features for)
some way to specify the features to fetch (either via feature services, which group features needed for a model version, or feature references)
Before beginning, you need to instantiate a local FeatureStore object that knows how to parse the registry (see more details)
For code examples of how the below work, inspect the generated repository from feast init -t [YOUR TEMPLATE] (gcp, snowflake, and aws are the most fully fleshed).
Before diving into how to retrieve features, we need to understand some high level concepts in Feast.
A feature service is an object that represents a logical group of features from one or more feature views. Feature Services allows features from within a feature view to be used as needed by an ML model. Users can expect to create one feature service per model version, allowing for tracking of the features used by models.
from driver_ratings_feature_view import driver_ratings_fv
from driver_trips_feature_view import driver_stats_fv
driver_stats_fs = FeatureService(
name="driver_activity",
features=[driver_stats_fv, driver_ratings_fv[["lifetime_rating"]]]
)
Feature services are used during
The generation of training datasets when querying feature views in order to find historical feature values. A single training dataset may consist of features from multiple feature views.
Retrieval of features for batch scoring from the offline store (e.g. with an entity dataframe where all timestamps are now())
Retrieval of features from the online store for online inference (with smaller batch sizes). The features retrieved from the online store may also belong to multiple feature views.
Feature services enable referencing all or some features from a feature view.
Retrieving from the online store with a feature service
Retrieving from the offline store with a feature service
This mechanism of retrieving features is only recommended as you're experimenting. Once you want to launch experiments or serve models, feature services are recommended.
Feature references uniquely identify feature values in Feast. The structure of a feature reference in string form is as follows: <feature_view>:<feature>
Feature references are used for the retrieval of features from Feast:
It is possible to retrieve features from multiple feature views with a single request, and Feast is able to join features from multiple tables in order to build a training dataset. However, it is not possible to reference (or retrieve) features from multiple projects at the same time.
The timestamp on which an event occurred, as found in a feature view's data source. The event timestamp describes the event time at which a feature was observed or generated.
Event timestamps are used during point-in-time joins to ensure that the latest feature values are joined from feature views onto entity rows. Event timestamps are also used to ensure that old feature values aren't served to models during online serving.
A dataset is a collection of rows that is produced by a historical retrieval from Feast in order to train a model. A dataset is produced by a join from one or more feature views onto an entity dataframe. Therefore, a dataset may consist of features from multiple feature views.
Dataset vs Feature View: Feature views contain the schema of data and a reference to where data can be found (through its data source). Datasets are the actual data manifestation of querying those data sources.
Dataset vs Data Source: Datasets are the output of historical retrieval, whereas data sources are the inputs. One or more data sources can be used in the creation of a dataset.
Feast abstracts away point-in-time join complexities with the get_historical_features API.
We go through the major steps, and also show example code. Note that the quickstart templates generally have end-to-end working examples for all these cases.
Feast accepts either:
feature services, which group features needed for a model version
Feast accepts either a Pandas dataframe as the entity dataframe (including entity keys and timestamps) or a SQL query to generate the entities.
Both approaches must specify the full entity key needed as well as the timestamps. Feast then joins features onto this dataframe.
You can also pass a SQL string to generate the above dataframe. This is useful for getting all entities in a timeframe from some data source.
Feast will ensure the latest feature values for registered features are available. At retrieval time, you need to supply a list of entities and the corresponding features to be retrieved. Similar to get_historical_features, we recommend using feature services as a mechanism for grouping features in a model version.
Note: unlike get_historical_features, the entity_rowsdo not need timestamps since you only want one feature value per entity key.
There are several options for retrieving online features: through the SDK, or through a feature server
Overview
from feast import FeatureStore
feature_store = FeatureStore('.') # Initialize the feature store
feature_service = feature_store.get_feature_service("driver_activity")
features = feature_store.get_online_features(
features=feature_service, entity_rows=[entity_dict]
)
from feast import FeatureStore
feature_store = FeatureStore('.') # Initialize the feature store
feature_service = feature_store.get_feature_service("driver_activity")
feature_store.get_historical_features(features=feature_service, entity_df=entity_df)
entity_sql = f"""
SELECT
driver_id,
event_timestamp
FROM {store.get_data_source("driver_hourly_stats_source").get_table_query_string()}
WHERE event_timestamp BETWEEN '2021-01-01' and '2021-12-31'
"""
training_df = store.get_historical_features(
entity_df=entity_sql,
features=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate",
"driver_daily_features:daily_miles_driven"
],
).to_df()
Concepts
Feature Services
Applying a feature service does not result in an actual service being deployed.
Feature References
Note, if you're using , then those features can be added here without additional entity values in the entity_rows parameter.
Event timestamp
Dataset
Retrieving historical features (for training data or batch scoring)
Full example: generate training data
Full example: retrieve offline features for batch scoring
The main difference here compared to training data generation is how to handle timestamps in the entity dataframe. You want to pass in the current time to get the latest feature values for all your entities.
Step 1: Specifying Features
Example: querying a feature service (recommended)
Example: querying a list of feature references
Step 2: Specifying Entities
Example: entity dataframe for generating training data
Example: entity SQL query for generating training data
Retrieving online features (for model inference)
Full example: retrieve online features for real-time model inference (Python SDK)
Full example: retrieve online features for real-time model inference (Feature Server)
This approach requires you to deploy a feature server (see ).
DynamoDB
The online store provides support for materializing feature values into AWS DynamoDB.
In order to use this online store, you'll need to run pip install 'feast[aws]'. You can then get started with the command feast init REPO_NAME -t aws.
The full set of configuration options is available in .
Feast requires the following permissions in order to execute commands for DynamoDB online store:
from feast import FeatureStore
store = FeatureStore(repo_path=".")
# Get the latest feature values for unique entities
entity_sql = f"""
SELECT
driver_id,
CURRENT_TIMESTAMP() as event_timestamp
FROM {store.get_data_source("driver_hourly_stats_source").get_table_query_string()}
WHERE event_timestamp BETWEEN '2021-01-01' and '2021-12-31'
GROUP BY driver_id
"""
batch_scoring_features = store.get_historical_features(
entity_df=entity_sql,
features=store.get_feature_service("model_v2"),
).to_df()
# predictions = model.predict(batch_scoring_features)
from feast import RepoConfig, FeatureStore
from feast.repo_config import RegistryConfig
repo_config = RepoConfig(
registry=RegistryConfig(path="gs://feast-test-gcs-bucket/registry.pb"),
project="feast_demo_gcp",
provider="gcp",
)
store = FeatureStore(config=repo_config)
features = store.get_online_features(
features=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate",
"driver_daily_features:daily_miles_driven",
],
entity_rows=[
{
"driver_id": 1001,
}
],
).to_dict()
The following inline policy can be used to grant Feast the necessary permissions:
Lastly, this IAM role needs to be associated with the desired Redshift cluster. Please follow the official AWS guide for the necessary steps here.
The set of functionality supported by online stores is described in detail here. Below is a matrix indicating which functionality is supported by the DynamoDB online store.
DynamoDB
write feature values to the online store
yes
read feature values from the online store
yes
update infrastructure (e.g. tables) in the online store
To compare this set of functionality against other online stores, please see the full functionality matrix.
teardown infrastructure (e.g. tables) in the online store
yes
generate a plan of infrastructure changes
no
support for on-demand transforms
yes
readable by Python SDK
yes
readable by Java
no
readable by Go
no
support for entityless feature views
yes
support for concurrent writing to the same key
no
support for ttl (time to live) at retrieval
no
support for deleting expired data
no
collocated by feature view
yes
collocated by feature service
no
collocated by entity key
no
Adding a new online store
Overview
Feast makes adding support for a new online store (database) easy. Developers can simply implement the OnlineStore interface to add support for a new store (other than the existing stores like Redis, DynamoDB, SQLite, and Datastore).
In this guide, we will show you how to integrate with MySQL as an online store. While we will be implementing a specific store, this guide should be representative for adding support for any new online store.
The process of using a custom online store consists of 6 steps:
Defining the OnlineStore class.
Defining the OnlineStoreConfig class.
Referencing the OnlineStore in a feature repo's feature_store.yaml file.
Testing the OnlineStore class.
Update dependencies.
Add documentation.
New online stores go in sdk/python/feast/infra/online_stores/contrib/.
Not guaranteed to implement all interface methods
Not guaranteed to be stable.
Should have warnings for users to indicate this is a contrib plugin that is not maintained by the maintainers.
To move an online store plugin out of contrib, you need:
GitHub actions (i.e make test-python-integration) is setup to run all tests against the online store and pass.
At least two contributors own the plugin (ideally tracked in our OWNERS / CODEOWNERS file).
The OnlineStore class broadly contains two sets of methods
One set deals with managing infrastructure that the online store needed for operations
One set deals with writing data into the store, and reading data from the store.
There are two methods that deal with managing infrastructure for online stores, update and teardown
update is invoked when users run feast apply as a CLI command, or the FeatureStore.apply() sdk method.
The update method should be used to perform any operations necessary before data can be written to or read from the store. The update method can be used to create MySQL tables in preparation for reads and writes to new feature views.
teardown is invoked when users run feast teardown or FeatureStore.teardown().
The teardown method should be used to perform any clean-up operations. teardown can be used to drop MySQL indices and tables corresponding to the feature views being deleted.
There are two methods that deal with writing data to and from the online stores.online_write_batch and online_read.
online_write_batch is invoked when running materialization (using the feast materialize or feast materialize-incremental commands, or the corresponding FeatureStore.materialize() method.
online_read is invoked when reading values from the online store using the FeatureStore.get_online_features()
Additional configuration may be needed to allow the OnlineStore to talk to the backing store. For example, MySQL may need configuration information like the host at which the MySQL instance is running, credentials for connecting to the database, etc.
To facilitate configuration, all OnlineStore implementations are required to also define a corresponding OnlineStoreConfig class in the same file. This OnlineStoreConfig class should inherit from the FeastConfigBaseModel class, which is defined .
The FeastConfigBaseModel is a class, which parses yaml configuration into python objects. Pydantic also allows the model classes to define validators for the config classes, to make sure that the config classes are correctly defined.
This config class must container a type field, which contains the fully qualified class name of its corresponding OnlineStore class.
Additionally, the name of the config class must be the same as the OnlineStore class, with the Config suffix.
An example of the config class for MySQL :
This configuration can be specified in the feature_store.yaml as follows:
This configuration information is available to the methods of the OnlineStore, via theconfig: RepoConfig parameter which is passed into all the methods of the OnlineStore interface, specifically at the config.online_store field of the config parameter.
After implementing both these classes, the custom online store can be used by referencing it in a feature repo's feature_store.yaml file, specifically in the online_store field. The value specified should be the fully qualified class name of the OnlineStore.
As long as your OnlineStore class is available in your Python environment, it will be imported by Feast dynamically at runtime.
To use our MySQL online store, we can use the following feature_store.yaml:
If additional configuration for the online store is **not **required, then we can omit the other fields and only specify the type of the online store class as the value for the online_store.
Even if you have created the OnlineStore class in a separate repo, you can still test your implementation against the Feast test suite, as long as you have Feast as a submodule in your repo.
In the Feast submodule, we can run all the unit tests and make sure they pass:
The universal tests, which are integration tests specifically intended to test offline and online stores, should be run against Feast to ensure that the Feast APIs works with your online store.
Feast parametrizes integration tests using the FULL_REPO_CONFIGS variable defined in
A sample FULL_REPO_CONFIGS_MODULE looks something like this:
If you are planning to start the online store up locally(e.g spin up a local Redis Instance) for testing, then the dictionary entry should be something like:
If you are planning instead to use a Dockerized container to run your tests against your online store, you can define a OnlineStoreCreator and replace the None object above with your OnlineStoreCreator class. You should make this class available to pytest through the PYTEST_PLUGINS environment variable.
If you create a containerized docker image for testing, developers who are trying to test with your online store will not have to spin up their own instance of the online store for testing. An example of an OnlineStoreCreator is shown below:
3. Add a Makefile target to the Makefile to run your datastore specific tests by setting the FULL_REPO_CONFIGS_MODULE environment variable. Add PYTEST_PLUGINS if pytest is having trouble loading your DataSourceCreator. You can remove certain tests that are not relevant or still do not work for your datastore using the -k option.
If there are some tests that fail, this indicates that there is a mistake in the implementation of this online store!
Add any dependencies for your online store to our sdk/python/setup.py under a new <ONLINE_STORE>_REQUIRED list with the packages and add it to the setup script so that if your online store is needed, users can install the necessary python packages. These packages should be defined as extras so that they are not installed by users by default.
You will need to regenerate our requirements files. To do this, create separate pyenv environments for python 3.8, 3.9, and 3.10. In each environment, run the following commands:
Remember to add the documentation for your online store.
Add a new markdown file to docs/reference/online-stores/.
You should also add a reference in docs/reference/online-stores/README.md and docs/SUMMARY.md. Add a new markdown document to document your online store functionality similar to how the other online stores are documented.
NOTE:Be sure to document the following things about your online store:
Be sure to cover how to create the datasource and what configuration is needed in the feature_store.yaml file in order to create the datasource.
Make sure to flag that the online store is in alpha development.
Add some documentation on what the data model is for the specific online store for more clarity.
Adding or reusing tests
This guide will go over:
how Feast tests are setup
how to extend the test suite to test new functionality
which stores different online store classes for testing.
To overwrite these configurations, you can simply create your own file that contains a FULL_REPO_CONFIGS variable, and point Feast to that file by setting the environment variable FULL_REPO_CONFIGS_MODULE to point to that file.
Finally, generate the python code docs by running:
1. Defining an OnlineStore class
OnlineStore class names must end with the OnlineStore suffix!
Contrib online stores
What is a contrib plugin?
How do I make a contrib plugin an "official" plugin?
1.1 Infrastructure Methods
1.2 Read/Write Methods
2. Defining an OnlineStoreConfig class
3. Using the custom online store
4. Testing the OnlineStore class
4.1 Integrating with the integration test suite and unit test suite.
# Only prints out runtime warnings once.
warnings.simplefilter("once", RuntimeWarning)
def update(
self,
config: RepoConfig,
tables_to_delete: Sequence[Union[FeatureTable, FeatureView]],
tables_to_keep: Sequence[Union[FeatureTable, FeatureView]],
entities_to_delete: Sequence[Entity],
entities_to_keep: Sequence[Entity],
partial: bool,
):
"""
An example of creating managing the tables needed for a mysql-backed online store.
"""
warnings.warn(
"This online store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
conn = self._get_conn(config)
cur = conn.cursor(buffered=True)
project = config.project
for table in tables_to_keep:
cur.execute(
f"CREATE TABLE IF NOT EXISTS {_table_id(project, table)} (entity_key VARCHAR(512), feature_name VARCHAR(256), value BLOB, event_ts timestamp, created_ts timestamp, PRIMARY KEY(entity_key, feature_name))"
)
cur.execute(
f"CREATE INDEX {_table_id(project, table)}_ek ON {_table_id(project, table)} (entity_key);"
)
for table in tables_to_delete:
cur.execute(
f"DROP INDEX {_table_id(project, table)}_ek ON {_table_id(project, table)};"
)
cur.execute(f"DROP TABLE IF EXISTS {_table_id(project, table)}")
def teardown(
self,
config: RepoConfig,
tables: Sequence[Union[FeatureTable, FeatureView]],
entities: Sequence[Entity],
):
warnings.warn(
"This online store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
conn = self._get_conn(config)
cur = conn.cursor(buffered=True)
project = config.project
for table in tables:
cur.execute(
f"DROP INDEX {_table_id(project, table)}_ek ON {_table_id(project, table)};"
)
cur.execute(f"DROP TABLE IF EXISTS {_table_id(project, table)}")
feast_custom_online_store/mysql.py
# Only prints out runtime warnings once.
warnings.simplefilter("once", RuntimeWarning)
def online_write_batch(
self,
config: RepoConfig,
table: Union[FeatureTable, FeatureView],
data: List[
Tuple[EntityKeyProto, Dict[str, ValueProto], datetime, Optional[datetime]]
],
progress: Optional[Callable[[int], Any]],
) -> None:
warnings.warn(
"This online store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
conn = self._get_conn(config)
cur = conn.cursor(buffered=True)
project = config.project
for entity_key, values, timestamp, created_ts in data:
entity_key_bin = serialize_entity_key(
entity_key,
entity_key_serialization_version=config.entity_key_serialization_version,
).hex()
timestamp = _to_naive_utc(timestamp)
if created_ts is not None:
created_ts = _to_naive_utc(created_ts)
for feature_name, val in values.items():
self.write_to_table(created_ts, cur, entity_key_bin, feature_name, project, table, timestamp, val)
self._conn.commit()
if progress:
progress(1)
def online_read(
self,
config: RepoConfig,
table: Union[FeatureTable, FeatureView],
entity_keys: List[EntityKeyProto],
requested_features: Optional[List[str]] = None,
) -> List[Tuple[Optional[datetime], Optional[Dict[str, ValueProto]]]]:
warnings.warn(
"This online store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
conn = self._get_conn(config)
cur = conn.cursor(buffered=True)
result: List[Tuple[Optional[datetime], Optional[Dict[str, ValueProto]]]] = []
project = config.project
for entity_key in entity_keys:
entity_key_bin = serialize_entity_key(
entity_key,
entity_key_serialization_version=config.entity_key_serialization_version,
).hex()
print(f"entity_key_bin: {entity_key_bin}")
cur.execute(
f"SELECT feature_name, value, event_ts FROM {_table_id(project, table)} WHERE entity_key = %s",
(entity_key_bin,),
)
res = {}
res_ts = None
for feature_name, val_bin, ts in cur.fetchall():
val = ValueProto()
val.ParseFromString(val_bin)
res[feature_name] = val
res_ts = ts
if not res:
result.append((None, None))
else:
result.append((res_ts, res))
return result
project: test_custom
registry: data/registry.db
provider: local
online_store:
# Make sure to specify the type as the fully qualified path that Feast can import.
type: feast_custom_online_store.mysql.MySQLOnlineStore
user: foo
password: bar
feature_repo/feature_store.yaml
project: test_custom
registry: data/registry.db
provider: local
online_store: feast_custom_online_store.mysql.MySQLOnlineStore
{
"sqlite": ({"type": "sqlite"}, None),
# Specifies sqlite as the online store. The `None` object specifies to not use a containerized docker container.
}
export PYTHON=<version>
make lock-python-ci-dependencies
make build-sphinx
how to use the existing test suite to test a new custom offline / online store
Unit tests are contained in sdk/python/tests/unit. Integration tests are contained in sdk/python/tests/integration. Let's inspect the structure of sdk/python/tests/integration:
feature_repos has setup files for most tests in the test suite.
conftest.py (in the parent directory) contains the most common fixtures, which are designed as an abstraction on top of specific offline/online stores, so tests do not need to be rewritten for different stores. Individual test files also contain more specific fixtures.
The tests are organized by which Feast component(s) they test.
The universal feature repo refers to a set of fixtures (e.g. environment and universal_data_sources) that can be parametrized to cover various combinations of offline stores, online stores, and providers. This allows tests to run against all these various combinations without requiring excess code. The universal feature repo is constructed by fixtures in conftest.py with help from the various files in feature_repos.
Tests in Feast are split into integration and unit tests. If a test requires external resources (e.g. cloud resources on GCP or AWS), it is an integration test. If a test can be run purely locally (where locally includes Docker resources), it is a unit test.
Integration tests test non-local Feast behavior. For example, tests that require reading data from BigQuery or materializing data to DynamoDB are integration tests. Integration tests also tend to involve more complex Feast functionality.
Unit tests test local Feast behavior. For example, tests that only require registering feature views are unit tests. Unit tests tend to only involve simple Feast functionality.
E2E tests
E2E tests test end-to-end functionality of Feast over the various codepaths (initialize a feature store, apply, and materialize).
The main codepaths include:
basic e2e tests for offline stores
test_universal_e2e.py
go feature server
test_go_feature_server.py
python http server
test_python_feature_server.py
usage tracking
test_usage_e2e.py
data quality monitoring feature validation
test_validation.py
Offline and Online Store Tests
Offline and online store tests mainly test for the offline and online retrieval functionality.
The various specific functionalities that are tested include:
Registration Tests
The registration folder contains all of the registry tests and some universal cli tests. This includes:
CLI Apply and Materialize tests tested against on the universal test suite
Miscellaneous Tests
AWS Lambda Materialization Tests (Currently do not work)
test_lambda.py
Registry Diff Tests
These are tests for the infrastructure and registry diff functionality that Feast uses to determine if changes to the registry or infrastructure is needed.
Local CLI Tests and Local Feast Tests
These tests test all of the cli commands against the local file offline store.
Infrastructure Unit Tests
DynamoDB tests with dynamo mocked out
Repository configuration tests
Feature Store Validation Tests
These test mainly contain class level validation like hashing tests, protobuf and class serialization, and error and warning handling.
Data source unit tests
Docstring tests are primarily smoke tests to make sure imports and setup functions can be executed without errors.
Let's look at a sample test using the universal repo:
@pytest.mark.integration
@pytest.mark.universal_offline_stores
@pytest.mark.parametrize("full_feature_names", [True, False], ids=lambda v: f"full:{v}")
def test_historical_features(environment, universal_data_sources, full_feature_names):
store = environment.feature_store
(entities, datasets, data_sources) = universal_data_sources
feature_views = construct_universal_feature_views(data_sources)
entity_df_with_request_data = datasets.entity_df.copy(deep=True)
entity_df_with_request_data["val_to_add"] = [
i for i in range(len(entity_df_with_request_data))
]
entity_df_with_request_data["driver_age"] = [
i + 100 for i in range(len(entity_df_with_request_data))
]
feature_service = FeatureService(
name="convrate_plus100",
features=[feature_views.driver[["conv_rate"]], feature_views.driver_odfv],
)
feature_service_entity_mapping = FeatureService(
name="entity_mapping",
features=[
feature_views.location.with_name("origin").with_join_key_map(
{"location_id": "origin_id"}
),
feature_views.location.with_name("destination").with_join_key_map(
{"location_id": "destination_id"}
),
],
)
store.apply(
[
driver(),
customer(),
location(),
feature_service,
feature_service_entity_mapping,
*feature_views.values(),
]
)
# ... more test code
job_from_df = store.get_historical_features(
entity_df=entity_df_with_request_data,
features=[
"driver_stats:conv_rate",
"driver_stats:avg_daily_trips",
"customer_profile:current_balance",
"customer_profile:avg_passenger_count",
"customer_profile:lifetime_trip_count",
"conv_rate_plus_100:conv_rate_plus_100",
"conv_rate_plus_100:conv_rate_plus_100_rounded",
"conv_rate_plus_100:conv_rate_plus_val_to_add",
"order:order_is_success",
"global_stats:num_rides",
"global_stats:avg_ride_length",
"field_mapping:feature_name",
],
full_feature_names=full_feature_names,
)
if job_from_df.supports_remote_storage_export():
files = job_from_df.to_remote_storage()
print(files)
assert len(files) > 0 # This test should be way more detailed
start_time = datetime.utcnow()
actual_df_from_df_entities = job_from_df.to_df()
# ... more test code
validate_dataframes(
expected_df,
table_from_df_entities,
sort_by=[event_timestamp, "order_id", "driver_id", "customer_id"],
event_timestamp = event_timestamp,
)
# ... more test code
The key fixtures are the environment and universal_data_sources fixtures, which are defined in the feature_repos directories and the conftest.py file. This by default pulls in a standard dataset with driver and customer entities (that we have pre-defined), certain feature views, and feature values.
The environment fixture sets up a feature store, parametrized by the provider and the online/offline store. It allows the test to query against that feature store without needing to worry about the underlying implementation or any setup that may be involved in creating instances of these datastores.
Each fixture creates a different integration test with its own IntegrationTestRepoConfig which is used by pytest to generate a unique test testing one of the different environments that require testing.
Feast tests also use a variety of markers:
The @pytest.mark.integration marker is used to designate integration tests which will cause the test to be run when you call make test-python-integration.
The @pytest.mark.universal_offline_stores
Use the same function signatures as an existing test (e.g. use environment and universal_data_sources as an argument) to include the relevant test fixtures.
If possible, expand an individual test instead of writing a new test, due to the cost of starting up offline / online stores.
Use the universal_offline_stores and universal_online_store markers to parametrize the test against different offline store and online store combinations. You can also designate specific online and offline stores to test by using the only parameter on the marker.
Install Feast in editable mode with pip install -e.
The core tests for offline / online store behavior are parametrized by the FULL_REPO_CONFIGS variable defined in feature_repos/repo_configuration.py. To overwrite this variable without modifying the Feast repo, create your own file that contains a FULL_REPO_CONFIGS (which will require adding a new IntegrationTestRepoConfig or two) and set the environment variable FULL_REPO_CONFIGS_MODULE to point to that file. Then the core offline / online store tests can be run with make test-python-universal.
See the and the for examples.
Many problems arise when implementing your data store's type conversion to interface with Feast datatypes.
You will need to correctly update inference.py so that Feast can infer your datasource schemas
You also need to update type_map.py so that Feast knows how to convert your datastores types to Feast-recognized types in feast/types.py.
The most important functionality in Feast is historical and online retrieval. Most of the e2e and universal integration test test this functionality in some way. Making sure this functionality works also indirectly asserts that reading and writing from your datastore works as intended.
Extend data_source_creator.py for your offline store.
In repo_configuration.py add a new IntegrationTestRepoConfig or two (depending on how many online stores you want to test).
Generally, you should only need to test against sqlite. However, if you need to test against a production online store, then you can also test against Redis or dynamodb.
Run the full test suite with make test-python-integration.
This folder is for plugins that are officially maintained with community owners. Place the APIs in feast/infra/offline_stores/contrib/.
Extend data_source_creator.py for your offline store and implement the required APIs.
In contrib_repo_configuration.py add a new IntegrationTestRepoConfig (depending on how many online stores you want to test).
Run the test suite on the contrib test suite with make test-python-contrib-universal.
In repo_configuration.py add a new config that maps to a serialized version of configuration you need in feature_store.yaml to setup the online store.
In repo_configuration.py, add new IntegrationTestRepoConfig for online stores you want to test.
Run the full test suite with make test-python-integration
Check test_universal_types.py for an example of how to do this.
Install Redis on your computer. If you are a mac user, you should be able to brew install redis.
Running redis-server --help and redis-cli --help should show corresponding help menus.
Run ./infra/scripts/redis-cluster.sh start then ./infra/scripts/redis-cluster.sh create to start the Redis cluster locally. You should see output that looks like this:
You should be able to run the integration tests and have the Redis cluster tests pass.
If you would like to run your own Redis cluster, you can run the above commands with your own specified ports and connect to the newly configured cluster.
To stop the cluster, run ./infra/scripts/redis-cluster.sh stop and then ./infra/scripts/redis-cluster.sh clean.
To test a new offline / online store from a plugin repo
What are some important things to keep in mind when adding a new offline / online store?
Type mapping/Inference
Historical and online retrieval
To include a new offline / online store in the main Feast repo
Including a new offline / online store in the main Feast repo from external plugins with community maintainers.
To include a new online store
To use custom data in a new test
Running your own Redis cluster for testing
push API tests
test_push_features_to_offline_store.py
test_push_features_to_online_store.py
test_offline_write.py
historical retrieval tests
test_universal_historical_retrieval.py
online retrieval tests
test_universal_online.py
data quality monitoring feature logging tests
test_feature_logging.py
online store tests
test_universal_online.py
Data type inference tests
Registry tests
Schema inference unit tests
Key serialization tests
Basic provider unit tests
Feature service unit tests
Feature service, feature view, and feature validation tests
Protobuf/json tests for Feast ValueTypes
Serialization tests
Type mapping
Feast types
Serialization tests due to this
Feast usage tracking unit tests
marker will parametrize the test on all of the universal offline stores including file, redshift, bigquery and snowflake.
The full_feature_names parametrization defines whether or not the test should reference features as their full feature name (fully qualified path) or just the feature name itself.
Deploy a local feature store with a Parquet file offline store and Sqlite online store.
Build a training dataset using our time series features from our Parquet files.
Adding a new offline store
Feast makes adding support for a new offline store easy. Developers can simply implement the interface to add support for a new store (other than the existing stores like Parquet files, Redshift, and Bigquery).
In this guide, we will show you how to extend the existing File offline store and use in a feature repo. While we will be implementing a specific store, this guide should be representative for adding support for any new offline store.
The full working code for this guide can be found at .
The process for using a custom offline store consists of 8 steps:
Ingest batch features ("materialization") and streaming features (via a Push API) into the online store.
Read the latest features from the offline store for batch scoring
Read the latest features from the online store for real-time inference.
Explore the (experimental) Feast UI
In this tutorial, we'll use Feast to generate training data and power online model inference for a ride-sharing driver satisfaction prediction model. Feast solves several common issues in this flow:
Training-serving skew and complex data joins: Feature values often exist across multiple tables. Joining these datasets can be complicated, slow, and error-prone.
Feast joins these tables with battle-tested logic that ensures point-in-time correctness so future feature values do not leak to models.
Online feature availability: At inference time, models often need access to features that aren't readily available and need to be precomputed from other data sources.
Feast manages deployment to a variety of online stores (e.g. DynamoDB, Redis, Google Cloud Datastore) and ensures necessary features are consistently available and freshly computed at inference time.
Feature and model versioning: Different teams within an organization are often unable to reuse features across projects, resulting in duplicate feature creation logic. Models have data dependencies that need to be versioned, for example when running A/B tests on model versions.
Feast enables discovery of and collaboration on previously used features and enables versioning of sets of features (via feature services).
(Experimental) Feast enables light-weight feature transformations so users can re-use transformation logic across online / offline use cases and across models.
Install the Feast SDK and CLI using pip:
In this tutorial, we focus on a local deployment. For a more in-depth guide on how to use Feast with Snowflake / GCP / AWS deployments, see Running Feast with Snowflake/GCP/AWS
pip install feast
Bootstrap a new feature repository using feast init from the command line.
feast init my_project
cd my_project/feature_repo
Creating a new Feast repository in /home/Jovyan/my_project.
Let's take a look at the resulting demo repo itself. It breaks down into
data/ contains raw demo parquet data
example_repo.py contains demo feature definitions
feature_store.yaml contains a demo setup configuring where data sources are
test_workflow.py showcases how to run all key Feast commands, including defining, retrieving, and pushing features. You can run this with python test_workflow.py.
project: my_project
# By default, the registry is a file (but can be turned into a more scalable SQL-backed registry)
registry: data/registry.db
# The provider primarily specifies default offline / online stores & storing the registry in a given cloud
provider: local
online_store:
type: sqlite
path: data/online_store.db
entity_key_serialization_version: 2
# This is an example feature definition file
from datetime import timedelta
import pandas as pd
from feast import (
Entity,
FeatureService,
FeatureView,
Field,
FileSource,
PushSource,
RequestSource,
)
from feast.on_demand_feature_view import on_demand_feature_view
from feast.types import Float32, Float64, Int64
# Define an entity for the driver. You can think of entity as a primary key used to
# fetch features.
driver = Entity(name="driver", join_keys=["driver_id"])
# Read data from parquet files. Parquet is convenient for local development mode. For
# production, you can use your favorite DWH, such as BigQuery. See Feast documentation
# for more info.
driver_stats_source = FileSource(
name="driver_hourly_stats_source",
path="%PARQUET_PATH%",
timestamp_field="event_timestamp",
created_timestamp_column="created",
)
# Our parquet files contain sample data that includes a driver_id column, timestamps and
# three feature column. Here we define a Feature View that will allow us to serve this
# data to our model online.
driver_stats_fv = FeatureView(
# The unique name of this feature view. Two feature views in a single
# project cannot have the same name
name="driver_hourly_stats",
entities=[driver],
ttl=timedelta(days=1),
# The list of features defined below act as a schema to both define features
# for both materialization of features into a store, and are used as references
# during retrieval for building a training dataset or serving features
schema=[
Field(name="conv_rate", dtype=Float32),
Field(name="acc_rate", dtype=Float32),
Field(name="avg_daily_trips", dtype=Int64),
],
online=True,
source=driver_stats_source,
# Tags are user defined key/value pairs that are attached to each
# feature view
tags={"team": "driver_performance"},
)
# Defines a way to push data (to be available offline, online or both) into Feast.
driver_stats_push_source = PushSource(
name="driver_stats_push_source",
batch_source=driver_stats_source,
)
# Define a request data source which encodes features / information only
# available at request time (e.g. part of the user initiated HTTP request)
input_request = RequestSource(
name="vals_to_add",
schema=[
Field(name="val_to_add", dtype=Int64),
Field(name="val_to_add_2", dtype=Int64),
],
)
# Define an on demand feature view which can generate new features based on
# existing feature views and RequestSource features
@on_demand_feature_view(
sources=[driver_stats_fv, input_request],
schema=[
Field(name="conv_rate_plus_val1", dtype=Float64),
Field(name="conv_rate_plus_val2", dtype=Float64),
],
)
def transformed_conv_rate(inputs: pd.DataFrame) -> pd.DataFrame:
df = pd.DataFrame()
df["conv_rate_plus_val1"] = inputs["conv_rate"] + inputs["val_to_add"]
df["conv_rate_plus_val2"] = inputs["conv_rate"] + inputs["val_to_add_2"]
return df
# This groups features into a model version
driver_activity_v1 = FeatureService(
name="driver_activity_v1",
features=[
driver_stats_fv[["conv_rate"]], # Sub-selects a feature from a feature view
transformed_conv_rate, # Selects all features from the feature view
],
)
driver_activity_v2 = FeatureService(
name="driver_activity_v2", features=[driver_stats_fv, transformed_conv_rate]
)
The feature_store.yaml file configures the key overall architecture of the feature store.
The provider value sets default offline and online stores.
The offline store provides the compute layer to process historical data (for generating training data & feature values for serving).
The online store is a low latency store of the latest feature values (for powering real-time inference).
Valid values for provider in feature_store.yaml are:
local: use a SQL registry or local file registry. By default, use a file / Dask based offline store + SQLite online store
gcp: use a SQL registry or GCS file registry. By default, use BigQuery (offline store) + Google Cloud Datastore (online store)
aws: use a SQL registry or S3 file registry. By default, use Redshift (offline store) + DynamoDB (online store)
Note that there are many other offline / online stores Feast works with, including Spark, Azure, Hive, Trino, and PostgreSQL via community plugins. See Third party integrations for all supported data sources.
The raw feature data we have in this demo is stored in a local parquet file. The dataset captures hourly stats of a driver in a ride-sharing app.
Demo parquet data: data/driver_stats.parquet
There's an included test_workflow.py file which runs through a full sample workflow:
Register feature definitions through feast apply
Generate a training dataset (using get_historical_features)
Generate features for batch scoring (using get_historical_features)
Ingest batch features into an online store (using materialize_incremental)
Fetch online features to power real time inference (using get_online_features)
Ingest streaming features into offline / online stores (using push)
Verify online features are updated / fresher
We'll walk through some snippets of code below and explain
The apply command scans python files in the current directory for feature view/entity definitions, registers the objects, and deploys infrastructure. In this example, it reads example_repo.py and sets up SQLite online store tables. Note that we had specified SQLite as the default online store by configuring online_store in feature_store.yaml.
feast apply
Created entity driver
Created feature view driver_hourly_stats
Created on demand feature view transformed_conv_rate
Created feature service driver_activity_v1
Created feature service driver_activity_v2
Created sqlite table my_project_driver_hourly_stats
To train a model, we need features and labels. Often, this label data is stored separately (e.g. you have one table storing user survey results and another set of tables with feature values). Feast can help generate the features that map to these labels.
Feast needs a list of entities (e.g. driver ids) and timestamps. Feast will intelligently join relevant tables to create the relevant feature vectors. There are two ways to generate this list:
The user can query that table of labels with timestamps and pass that into Feast as an entity dataframe for training data generation.
The user can also query that table with a SQL query which pulls entities. See the documentation on feature retrieval for details
Note that we include timestamps because we want the features for the same driver at various timestamps to be used in a model.
from datetime import datetime
import pandas as pd
from feast import FeatureStore
# Note: see https://docs.feast.dev/getting-started/concepts/feature-retrieval for
# more details on how to retrieve for all entities in the offline store instead
entity_df = pd.DataFrame.from_dict(
{
# entity's join key -> entity values
"driver_id": [1001, 1002, 1003],
# "event_timestamp" (reserved key) -> timestamps
"event_timestamp": [
datetime(2021, 4, 12, 10, 59, 42),
datetime(2021, 4, 12, 8, 12, 10),
datetime(2021, 4, 12, 16, 40, 26),
],
# (optional) label name -> label values. Feast does not process these
"label_driver_reported_satisfaction": [1, 5, 3],
# values we're using for an on-demand transformation
"val_to_add": [1, 2, 3],
"val_to_add_2": [10, 20, 30],
}
)
store = FeatureStore(repo_path=".")
training_df = store.get_historical_features(
entity_df=entity_df,
features=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate",
"driver_hourly_stats:avg_daily_trips",
"transformed_conv_rate:conv_rate_plus_val1",
"transformed_conv_rate:conv_rate_plus_val2",
],
).to_df()
print("----- Feature schema -----\n")
print(training_df.info())
print()
print("----- Example features -----\n")
print(training_df.head())
We now serialize the latest values of features since the beginning of time to prepare for serving (note: materialize-incremental serializes all new features since the last materialize call).
Materializing 1 feature views to 2021-08-23 16:25:46+00:00 into the sqlite online
store.
driver_hourly_stats from 2021-08-22 16:25:47+00:00 to 2021-08-23 16:25:46+00:00:
100%|████████████████████████████████████████████| 5/5 [00:00<00:00, 592.05it/s]
At inference time, we need to quickly read the latest feature values for different drivers (which otherwise might have existed only in batch sources) from the online feature store using get_online_features(). These feature vectors can then be fed to the model.
from pprint import pprint
from feast import FeatureStore
store = FeatureStore(repo_path=".")
feature_vector = store.get_online_features(
features=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate",
"driver_hourly_stats:avg_daily_trips",
],
entity_rows=[
# {join_key: entity_value}
{"driver_id": 1004},
{"driver_id": 1005},
],
).to_dict()
pprint(feature_vector)
You can also use feature services to manage multiple features, and decouple feature view definitions and the features needed by end applications. The feature store can also be used to fetch either online or historical features using the same API below. More information can be found here.
The driver_activity_v1 feature service pulls all features from the driver_hourly_stats feature view:
from pprint import pprint
from feast import FeatureStore
feature_store = FeatureStore('.') # Initialize the feature store
feature_service = feature_store.get_feature_service("driver_activity_v1")
feature_vector = feature_store.get_online_features(
features=feature_service,
entity_rows=[
# {join_key: entity_value}
{"driver_id": 1004},
{"driver_id": 1005},
],
).to_dict()
pprint(feature_vector)
View all registered features, data sources, entities, and feature services with the Web UI.
One of the ways to view this is with the feast ui command.
feast ui
INFO: Started server process [66664]
08/17/2022 01:25:49 PM uvicorn.error INFO: Started server process [66664]
INFO: Waiting for application startup.
08/17/2022 01:25:49 PM uvicorn.error INFO: Waiting for application startup.
INFO: Application startup complete.
08/17/2022 01:25:49 PM uvicorn.error INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8888 (Press CTRL+C to quit)
08/17/2022 01:25:49 PM uvicorn.error INFO: Uvicorn running on http://0.0.0.0:8888 (Press CTRL+C to quit)
Take a look at test_workflow.py again. It showcases many sample flows on how to interact with Feast. You'll see these show up in the upcoming concepts + architecture + tutorial pages as well.
Read the Concepts page to understand the Feast data model.
Check out our Tutorials section for more examples on how to use Feast.
Follow our guide for a more in-depth tutorial on using Feast.
import pandas as pd
pd.read_parquet("data/driver_stats.parquet")
from feast import FeatureService
driver_stats_fs = FeatureService(
name="driver_activity_v1", features=[driver_hourly_stats_view]
)
Overview
Step 1: Install Feast
Step 2: Create a feature repository
Inspecting the raw data
Step 3: Run sample workflow
Step 3a: Register feature definitions and deploy your feature store
Step 3b: Generating training data or powering batch scoring models
Generating training data
Run offline inference (batch scoring)
Step 3c: Ingest batch features into your online store
Step 3d: Fetching feature vectors for inference
Step 3e: Using a feature service to fetch online features instead.
Step 4: Browse your features with the Web UI (experimental)
Step 5: Re-examine test_workflow.py
Next steps
Defining an
OfflineStore
class.
Defining an OfflineStoreConfig class.
Defining a RetrievalJob class for this offline store.
Defining a DataSource class for the offline store
Referencing the OfflineStore in a feature repo's feature_store.yaml file.
Testing the OfflineStore class.
Updating dependencies.
Adding documentation.
New offline stores go in sdk/python/feast/infra/offline_stores/contrib/.
Not guaranteed to implement all interface methods
Not guaranteed to be stable.
Should have warnings for users to indicate this is a contrib plugin that is not maintained by the maintainers.
To move an offline store plugin out of contrib, you need:
GitHub actions (i.e make test-python-integration) is setup to run all tests against the offline store and pass.
At least two contributors own the plugin (ideally tracked in our OWNERS / CODEOWNERS file).
The OfflineStore class contains a couple of methods to read features from the offline store. Unlike the OnlineStore class, Feast does not manage any infrastructure for the offline store.
To fully implement the interface for the offline store, you will need to implement these methods:
pull_latest_from_table_or_query is invoked when running materialization (using the feast materialize or feast materialize-incremental commands, or the corresponding FeatureStore.materialize() method. This method pull data from the offline store, and the FeatureStore class takes care of writing this data into the online store.
get_historical_features is invoked when reading values from the offline store using the FeatureStore.get_historical_features() method. Typically, this method is used to retrieve features when training ML models.
(optional) offline_write_batch is a method that supports directly pushing a pyarrow table to a feature view. Given a feature view with a specific schema, this function should write the pyarrow table to the batch source defined. More details about the push api can be found . This method only needs implementation if you want to support the push api in your offline store.
(optional) pull_all_from_table_or_query is a method that pulls all the data from an offline store from a specified start date to a specified end date. This method is only used for SavedDatasets as part of data quality monitoring validation.
(optional) write_logged_features is a method that takes a pyarrow table or a path that points to a parquet file and writes the data to a defined source defined by LoggingSource and LoggingConfig. This method is only used internally for SavedDatasets.
Most offline stores will have to perform some custom mapping of offline store datatypes to feast value types.
The function to implement here are source_datatype_to_feast_value_type and get_column_names_and_types in your DataSource class.
source_datatype_to_feast_value_type is used to convert your DataSource's datatypes to feast value types.
get_column_names_and_types retrieves the column names and corresponding datasource types.
Add any helper functions for type conversion to sdk/python/feast/type_map.py.
Be sure to implement correct type mapping so that Feast can process your feature columns without casting incorrectly that can potentially cause loss of information or incorrect data.
Additional configuration may be needed to allow the OfflineStore to talk to the backing store. For example, Redshift needs configuration information like the connection information for the Redshift instance, credentials for connecting to the database, etc.
To facilitate configuration, all OfflineStore implementations are required to also define a corresponding OfflineStoreConfig class in the same file. This OfflineStoreConfig class should inherit from the FeastConfigBaseModel class, which is defined here.
The FeastConfigBaseModel is a pydantic class, which parses yaml configuration into python objects. Pydantic also allows the model classes to define validators for the config classes, to make sure that the config classes are correctly defined.
This config class must container a type field, which contains the fully qualified class name of its corresponding OfflineStore class.
Additionally, the name of the config class must be the same as the OfflineStore class, with the Config suffix.
An example of the config class for the custom file offline store :
This configuration can be specified in the feature_store.yaml as follows:
This configuration information is available to the methods of the OfflineStore, via the config: RepoConfig parameter which is passed into the methods of the OfflineStore interface, specifically at the config.offline_store field of the config parameter. This fields in the feature_store.yaml should map directly to your OfflineStoreConfig class that is detailed above in Section 2.
The offline store methods aren't expected to perform their read operations eagerly. Instead, they are expected to execute lazily, and they do so by returning a RetrievalJob instance, which represents the execution of the actual query against the underlying store.
Custom offline stores may need to implement their own instances of the RetrievalJob interface.
The RetrievalJob interface exposes two methods - to_df and to_arrow. The expectation is for the retrieval job to be able to return the rows read from the offline store as a parquet DataFrame, or as an Arrow table respectively.
Users who want to have their offline store support scalable batch materialization for online use cases (detailed in this RFC) will also need to implement to_remote_storage to distribute the reading and writing of offline store records to blob storage (such as S3). This may be used by a custom Materialization Engine to parallelize the materialization of data by processing it in chunks. If this is not implemented, Feast will default to local materialization (pulling all records into memory to materialize).
Before this offline store can be used as the batch source for a feature view in a feature repo, a subclass of the DataSourcebase class needs to be defined. This class is responsible for holding information needed by specific feature views to support reading historical values from the offline store. For example, a feature view using Redshift as the offline store may need to know which table contains historical feature values.
The data source class should implement two methods - from_proto, and to_proto.
For custom offline stores that are not being implemented in the main feature repo, the custom_options field should be used to store any configuration needed by the data source. In this case, the implementer is responsible for serializing this configuration into bytes in the to_proto method and reading the value back from bytes in the from_proto method.
After implementing these classes, the custom offline store can be used by referencing it in a feature repo's feature_store.yaml file, specifically in the offline_store field. The value specified should be the fully qualified class name of the OfflineStore.
As long as your OfflineStore class is available in your Python environment, it will be imported by Feast dynamically at runtime.
To use our custom file offline store, we can use the following feature_store.yaml:
If additional configuration for the offline store is not required, then we can omit the other fields and only specify the type of the offline store class as the value for the offline_store.
Finally, the custom data source class can be use in the feature repo to define a data source, and refer to in a feature view definition.
Even if you have created the OfflineStore class in a separate repo, you can still test your implementation against the Feast test suite, as long as you have Feast as a submodule in your repo.
In order to test against the test suite, you need to create a custom DataSourceCreator that implement our testing infrastructure methods, create_data_source and optionally, created_saved_dataset_destination.
create_data_source should create a datasource based on the dataframe passed in. It may be implemented by uploading the contents of the dataframe into the offline store and returning a datasource object pointing to that location. See BigQueryDataSourceCreator for an implementation of a data source creator.
created_saved_dataset_destination is invoked when users need to save the dataset for use in data validation. This functionality is still in alpha and is optional.
Make sure that your offline store doesn't break any unit tests first by running:
Next, set up your offline store to run the universal integration tests. These are integration tests specifically intended to test offline and online stores against Feast API functionality, to ensure that the Feast APIs works with your offline store.
Feast parametrizes integration tests using the FULL_REPO_CONFIGS variable defined in sdk/python/tests/integration/feature_repos/repo_configuration.py which stores different offline store classes for testing.
You should swap out the FULL_REPO_CONFIGS environment variable and run the integration tests against your offline store. In the example repo, the file that overwrites FULL_REPO_CONFIGS is feast_custom_offline_store/feast_tests.py, so you would run:
If the integration tests fail, this indicates that there is a mistake in the implementation of this offline store!
Remember to add your datasource to repo_config.py similar to how we added spark, trino, etc, to the dictionary OFFLINE_STORE_CLASS_FOR_TYPE. This will allow Feast to load your class from the feature_store.yaml.
Finally, add a Makefile target to the Makefile to run your datastore specific tests by setting the FULL_REPO_CONFIGS_MODULE and PYTEST_PLUGINS environment variable. The PYTEST_PLUGINS environment variable allows pytest to load in the DataSourceCreator for your datasource. You can remove certain tests that are not relevant or still do not work for your datastore using the -k option.
Add any dependencies for your offline store to our sdk/python/setup.py under a new <OFFLINE_STORE>__REQUIRED list with the packages and add it to the setup script so that if your offline store is needed, users can install the necessary python packages. These packages should be defined as extras so that they are not installed by users by default. You will need to regenerate our requirements files. To do this, create separate pyenv environments for python 3.8, 3.9, and 3.10. In each environment, run the following commands:
Remember to add documentation for your offline store.
Add a new markdown file to docs/reference/offline-stores/ and docs/reference/data-sources/. Use these files to document your offline store functionality similar to how the other offline stores are documented.
You should also add a reference in docs/reference/data-sources/README.md and docs/SUMMARY.md to these markdown files.
NOTE: Be sure to document the following things about your offline store:
How to create the datasource and most what configuration is needed in the feature_store.yaml file in order to create the datasource.
Make sure to flag that the datasource is in alpha development.
Add some documentation on what the data model is for the specific offline store for more clarity.
Finally, generate the python code docs by running:
# Only prints out runtime warnings once.
warnings.simplefilter("once", RuntimeWarning)
def get_historical_features(self,
config: RepoConfig,
feature_views: List[FeatureView],
feature_refs: List[str],
entity_df: Union[pd.DataFrame, str],
registry: Registry, project: str,
full_feature_names: bool = False) -> RetrievalJob:
""" Perform point-in-time correct join of features onto an entity dataframe(entity key and timestamp). More details about how this should work at https://docs.feast.dev/v/v0.6-branch/user-guide/feature-retrieval#3.-historical-feature-retrieval.
print("Getting historical features from my offline store")."""
warnings.warn(
"This offline store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
# Implementation here.
pass
def pull_latest_from_table_or_query(self,
config: RepoConfig,
data_source: DataSource,
join_key_columns: List[str],
feature_name_columns: List[str],
timestamp_field: str,
created_timestamp_column: Optional[str],
start_date: datetime,
end_date: datetime) -> RetrievalJob:
""" Pulls data from the offline store for use in materialization."""
print("Pulling latest features from my offline store")
warnings.warn(
"This offline store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
# Implementation here.
pass
def pull_all_from_table_or_query(
config: RepoConfig,
data_source: DataSource,
join_key_columns: List[str],
feature_name_columns: List[str],
timestamp_field: str,
start_date: datetime,
end_date: datetime,
) -> RetrievalJob:
""" Optional method that returns a Retrieval Job for all join key columns, feature name columns, and the event timestamp columns that occur between the start_date and end_date."""
warnings.warn(
"This offline store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
# Implementation here.
pass
def write_logged_features(
config: RepoConfig,
data: Union[pyarrow.Table, Path],
source: LoggingSource,
logging_config: LoggingConfig,
registry: BaseRegistry,
):
""" Optional method to have Feast support logging your online features."""
warnings.warn(
"This offline store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
# Implementation here.
pass
def offline_write_batch(
config: RepoConfig,
feature_view: FeatureView,
table: pyarrow.Table,
progress: Optional[Callable[[int], Any]],
):
""" Optional method to have Feast support the offline push api for your offline store."""
warnings.warn(
"This offline store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
# Implementation here.
pass
feast_custom_offline_store/file.py
class CustomFileOfflineStoreConfig(FeastConfigBaseModel):
""" Custom offline store config for local (file-based) store """
type: Literal["feast_custom_offline_store.file.CustomFileOfflineStore"] \
= "feast_custom_offline_store.file.CustomFileOfflineStore"
uri: str # URI for your offline store(in this case it would be a path)
def get_historical_features(self,
config: RepoConfig,
feature_views: List[FeatureView],
feature_refs: List[str],
entity_df: Union[pd.DataFrame, str],
registry: Registry, project: str,
full_feature_names: bool = False) -> RetrievalJob:
warnings.warn(
"This offline store is an experimental feature in alpha development. "
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
offline_store_config = config.offline_store
assert isinstance(offline_store_config, CustomFileOfflineStoreConfig)
store_type = offline_store_config.type
feast_custom_offline_store/file.py
class CustomFileRetrievalJob(RetrievalJob):
def __init__(self, evaluation_function: Callable):
"""Initialize a lazy historical retrieval job"""
# The evaluation function executes a stored procedure to compute a historical retrieval.
self.evaluation_function = evaluation_function
def to_df(self):
# Only execute the evaluation function to build the final historical retrieval dataframe at the last moment.
print("Getting a pandas DataFrame from a File is easy!")
df = self.evaluation_function()
return df
def to_arrow(self):
# Only execute the evaluation function to build the final historical retrieval dataframe at the last moment.
print("Getting a pandas DataFrame from a File is easy!")
df = self.evaluation_function()
return pyarrow.Table.from_pandas(df)
def to_remote_storage(self):
# Optional method to write to an offline storage location to support scalable batch materialization.
pass
feast_custom_offline_store/file.py
class CustomFileDataSource(FileSource):
"""Custom data source class for local files"""
def __init__(
self,
timestamp_field: Optional[str] = "",
path: Optional[str] = None,
field_mapping: Optional[Dict[str, str]] = None,
created_timestamp_column: Optional[str] = "",
date_partition_column: Optional[str] = "",
):
"Some functionality may still be unstable so functionality can change in the future.",
RuntimeWarning,
)
super(CustomFileDataSource, self).__init__(
timestamp_field=timestamp_field,
created_timestamp_column,
field_mapping,
date_partition_column,
)
self._path = path
@staticmethod
def from_proto(data_source: DataSourceProto):
custom_source_options = str(
data_source.custom_options.configuration, encoding="utf8"
)
path = json.loads(custom_source_options)["path"]
return CustomFileDataSource(
field_mapping=dict(data_source.field_mapping),
path=path,
timestamp_field=data_source.timestamp_field,
created_timestamp_column=data_source.created_timestamp_column,
date_partition_column=data_source.date_partition_column,
)
def to_proto(self) -> DataSourceProto:
config_json = json.dumps({"path": self.path})
data_source_proto = DataSourceProto(
type=DataSourceProto.CUSTOM_SOURCE,
custom_options=DataSourceProto.CustomSourceOptions(
configuration=bytes(config_json, encoding="utf8")
),
)
data_source_proto.timestamp_field = self.timestamp_field
data_source_proto.created_timestamp_column = self.created_timestamp_column
data_source_proto.date_partition_column = self.date_partition_column
return data_source_proto
feature_repo/feature_store.yaml
project: test_custom
registry: data/registry.db
provider: local
offline_store:
# Make sure to specify the type as the fully qualified path that Feast can import.
type: feast_custom_offline_store.file.CustomFileOfflineStore
feature_repo/feature_store.yaml
project: test_custom
registry: data/registry.db
provider: local
offline_store: feast_custom_offline_store.file.CustomFileOfflineStore
test-python-universal-spark:
PYTHONPATH='.' \
FULL_REPO_CONFIGS_MODULE=sdk.python.feast.infra.offline_stores.contrib.spark_repo_configuration \
PYTEST_PLUGINS=feast.infra.offline_stores.contrib.spark_offline_store.tests \
FEAST_USAGE=False IS_TEST=True \
python -m pytest -n 8 --integration \
-k "not test_historical_retrieval_fails_on_validation and \
not test_historical_retrieval_with_validation and \
not test_historical_features_persisting and \
not test_historical_retrieval_fails_on_validation and \
not test_universal_cli and \
not test_go_feature_server and \
not test_feature_logging and \
not test_reorder_columns and \
not test_logged_features_validation and \
not test_lambda_materialization_consistency and \
not test_offline_write and \
not test_push_features_to_offline_store.py and \
not gcs_registry and \
not s3_registry and \
not test_universal_types" \
sdk/python/tests
export PYTHON=<version>
make lock-python-ci-dependencies
make build-sphinx
1. Defining an OfflineStore class
OfflineStore class names must end with the OfflineStore suffix!
Contrib offline stores
What is a contrib plugin?
How do I make a contrib plugin an "official" plugin?
Define the offline store class
1.1 Type Mapping
2. Defining an OfflineStoreConfig class
3. Defining a RetrievalJob class
4. Defining a DataSource class for the offline store
5. Using the custom offline store
6. Testing the OfflineStore class
Integrating with the integration test suite and unit test suite.
7. Dependencies
8. Add Documentation
To overwrite the default configurations to use your own offline store, you can simply create your own file that contains a FULL_REPO_CONFIGS dictionary, and point Feast to that file by setting the environment variable FULL_REPO_CONFIGS_MODULE to point to that file. The module should add new IntegrationTestRepoConfig classes to the AVAILABLE_OFFLINE_STORES by defining an offline store that you would like Feast to test with.
A sample FULL_REPO_CONFIGS_MODULE looks something like this:
export FULL_REPO_CONFIGS_MODULE='feast_custom_offline_store.feast_tests'
make test-python-universal
# Should go in sdk/python/feast/infra/offline_stores/contrib/postgres_repo_configuration.py
from feast.infra.offline_stores.contrib.postgres_offline_store.tests.data_source import (
PostgreSQLDataSourceCreator,
)
AVAILABLE_OFFLINE_STORES = [("local", PostgreSQLDataSourceCreator)]
Validating historical features with Great Expectations
In this tutorial, we will use the public dataset of Chicago taxi trips to present data validation capabilities of Feast.
The original dataset is stored in BigQuery and consists of raw data for each taxi trip (one row per trip) since 2013.
We will generate several training datasets (aka historical features in Feast) for different periods and evaluate expectations made on one dataset against another.
Types of features we're ingesting and generating:
Features that aggregate raw data with daily intervals (eg, trips per day, average fare or speed for a specific day, etc.).
Features using SQL while pulling data from BigQuery (like total trips time or total miles travelled).
Features calculated on the fly when requested using Feast's on-demand transformations
Our plan:
Prepare environment
Pull data from BigQuery (optional)
Declare & apply features and feature views in Feast
The original notebook and datasets for this tutorial can be found on .
Install Feast Python SDK and great expectations:
You can skip this step if you don't have GCP account. Please use parquet files that are coming with this tutorial instead
Running some basic aggregations while pulling data from BigQuery. Grouping by taxi_id and day:
Read more about feature views in
Read more about on demand feature views
Generating range of timestamps with daily frequency:
Cross merge (aka relation multiplication) produces entity dataframe with each taxi_id repeated for each timestamp:
taxi_id
event_timestamp
156984 rows × 2 columns
Retrieving historical features for resulting entity dataframe and persisting output as a saved dataset:
Dataset profiler is a function that accepts dataset and generates set of its characteristics. This charasteristics will be then used to evaluate (validate) next datasets.
Important: datasets are not compared to each other! Feast use a reference dataset and a profiler function to generate a reference profile. This profile will be then used during validation of the tested dataset.
Loading saved dataset first and exploring the data:
total_earned
avg_trip_seconds
taxi_id
total_miles_travelled
trip_count
earned_per_hour
event_timestamp
total_trip_seconds
avg_fare
avg_speed
156984 rows × 10 columns
Feast uses as a validation engine and as a dataset's profile. Hence, we need to develop a function that will generate ExpectationSuite. This function will receive instance of (wrapper around pandas.DataFrame) so we can utilize both Pandas DataFrame API and some helper functions from PandasDataset during profiling.
Testing our profiler function:
Verify that all expectations that we coded in our profiler are present here. Otherwise (if you can't find some expectations) it means that it failed to pass on the reference dataset (do it silently is default behavior of Great Expectations).
Now we can create validation reference from dataset and profiler function:
and test it against our existing retrieval job
Validation successfully passed as no exception were raised.
Creating new timestamps for Dec 2020:
taxi_id
event_timestamp
35448 rows × 2 columns
Execute retrieval job with validation reference:
Validation failed since several expectations didn't pass:
Trip count (mean) decreased more than 10% (which is expected when comparing Dec 2020 vs June 2019)
Average Fare increased - all quantiles are higher than expected
Earn per hour (mean) increased more than 10% (most probably due to increased fare)
Generate reference dataset
Develop & test profiler function
Run validation on different dataset using reference dataset & profiler
2
91d5288487e87c5917b813ba6f75ab1c3a9749af906a2d...
2019-06-03
3
91d5288487e87c5917b813ba6f75ab1c3a9749af906a2d...
2019-06-04
4
91d5288487e87c5917b813ba6f75ab1c3a9749af906a2d...
2019-06-05
...
...
...
156979
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2019-06-27
156980
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2019-06-28
156981
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2019-06-29
156982
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2019-06-30
156983
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2019-07-01
0
68.25
2270.000000
91d5288487e87c5917b813ba6f75ab1c3a9749af906a2d...
24.70
2.0
54.118943
2019-06-01 00:00:00+00:00
4540.0
34.125000
2
91d5288487e87c5917b813ba6f75ab1c3a9749af906a2d...
2020-12-03
3
91d5288487e87c5917b813ba6f75ab1c3a9749af906a2d...
2020-12-04
4
91d5288487e87c5917b813ba6f75ab1c3a9749af906a2d...
2020-12-05
...
...
...
35443
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2020-12-03
35444
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2020-12-04
35445
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2020-12-05
35446
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2020-12-06
35447
7ebf27414a0c7b128e7925e1da56d51a8b81484f7630cf...
2020-12-07
!pip install 'feast[ge]'
!pip install google-cloud-bigquery
import pyarrow.parquet
from google.cloud.bigquery import Client
bq_client = Client(project='kf-feast')
data_query = """SELECT
taxi_id,
TIMESTAMP_TRUNC(trip_start_timestamp, DAY) as day,
SUM(trip_miles) as total_miles_travelled,
SUM(trip_seconds) as total_trip_seconds,
SUM(fare) as total_earned,
COUNT(*) as trip_count
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
trip_miles > 0 AND trip_seconds > 60 AND
trip_start_timestamp BETWEEN '2019-01-01' and '2020-12-31' AND
trip_total < 1000
GROUP BY taxi_id, TIMESTAMP_TRUNC(trip_start_timestamp, DAY)"""
def entities_query(year):
return f"""SELECT
distinct taxi_id
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
trip_miles > 0 AND trip_seconds > 0 AND
trip_start_timestamp BETWEEN '{year}-01-01' and '{year}-12-31'
"""
import pyarrow.parquet
import pandas as pd
from feast import FeatureView, Entity, FeatureStore, Field, BatchFeatureView
from feast.types import Float64, Int64
from feast.value_type import ValueType
from feast.data_format import ParquetFormat
from feast.on_demand_feature_view import on_demand_feature_view
from feast.infra.offline_stores.file_source import FileSource
from feast.infra.offline_stores.file import SavedDatasetFileStorage
from datetime import timedelta
batch_source = FileSource(
timestamp_field="day",
path="trips_stats.parquet", # using parquet file that we created on previous step
file_format=ParquetFormat()
)
import numpy as np
from feast.dqm.profilers.ge_profiler import ge_profiler
from great_expectations.core.expectation_suite import ExpectationSuite
from great_expectations.dataset import PandasDataset